Zygote进程
What is the Zygote copy-on-write heap?
All “Zygote-based” processes have memory pages that are identical among them.
Those pages are not copied, instead everything is linked to the same memory page. This reduces the amount on RAM used by all the “Zygote-based” processes.
If one of those process writes new data into such a page the page is automatically copied before the write actually takes place (because otherwise the memory of all forks would be changed).
This mechanism is called copy-on-write.
https://en.wikipedia.org/wiki/Copy-on-write
Copy-on-write From Wikipedia, the free encyclopedia
Copy-on-write (CoW or COW), sometimes referred to as implicit sharing[1] or shadowing,[2] is a resource-management technique used in computer programming to efficiently implement a “duplicate” or “copy” operation on modifiable resources.[3] If a resource is duplicated but not modified, it is not necessary to create a new resource; the resource can be shared between the copy and the original. Modifications must still create a copy, hence the technique: the copy operation is deferred to the first write. By sharing resources in this way, it is possible to significantly reduce the resource consumption of unmodified copies, while adding a small overhead to resource-modifying operations.
In virtual memory management Copy-on-write finds its main use in sharing the virtual memory of operating system processes, in the implementation of the fork system call. Typically, the process does not modify any memory and immediately executes a new process, replacing the address space entirely. Thus, it would be wasteful to copy all of the process’s memory during a fork, and instead the copy-on-write technique is used.
Copy-on-write can be implemented efficiently using the page table by marking certain pages of memory as read-only and keeping a count of the number of references to the page. When data is written to these pages, the kernel intercepts the write attempt and allocates a new physical page, initialized with the copy-on-write data, although the allocation can be skipped if there is only one reference. The kernel then updates the page table with the new (writable) page, decrements the number of references, and performs the write. The new allocation ensures that a change in the memory of one process is not visible in another’s.
In multithreaded systems, COW can be implemented without the use of traditional locking and instead use compare-and-swap to increment or decrement the internal reference counter. Since the original resource will never be altered, it can safely be copied by multiple threads (after the reference count was increased) without the need of performance-expensive locking such as mutexes.
Each app process is forked from an existing process called Zygote. The Zygote process starts when the system boots and loads common framework code and resources (such as activity themes). To start a new app process, the system forks the Zygote process then loads and runs the app’s code in the new process. This approach allows most of the RAM pages allocated for framework code and resources to be shared across all app processes.
Most static data is mmapped into a process. This technique allows data to be shared between processes, and also allows it to be paged out when needed. Example static data include: Dalvik code (by placing it in a pre-linked .odex file for direct mmapping), app resources (by designing the resource table to be a structure that can be mmapped and by aligning the zip entries of the APK), and traditional project elements like native code in .so files.
n many places, Android shares the same dynamic RAM across processes using explicitly allocated shared memory regions (either with ashmem or gralloc). For example, window surfaces use shared memory between the app and screen compositor, and cursor buffers use shared memory between the content provider and client.
4.4 Zygote的分裂 前文已经讲道,Zygote分裂出嫡长子system_server后,就通过runSelectLoopMode等待并处理来自客户的消息,那么,谁会向Zygote发送消息呢?这里,以一个Activity的启动为例,具体分析Zygote是如何分裂和繁殖的。
4.4.1 ActivityManagerService发送请求 ActivityManagerService也是由SystemServer创建的。假设通过startActivit来启动一个新的Activity,而这个Activity附属于一个还未启动的进程,那么这个进程该如何启动呢?先来看看ActivityManagerService中的startProcessLocked函数,代码如下所示:
4.4.2 有求必应之响应请求 前面有一节,题目叫“有求必应之等待请求”,那么这一节“有求必应之响应请求”会回到ZygoteInit。下面就看看它是如何处理请求的。
Zygote分裂子进程后,自己将在handleParentProc中做一些扫尾工作,然后继续等待请求进行下一次分裂。
这个android.app.ActivityThread类,实际上是Android中apk程序所对应的进程,它的main函数就是apk程序的main函数。从这个类的命名(android.app)中也可以看出些端倪。
通过这一节的分析,读者可以想到,Android系统运行的那些apk程序,其父都是zygote。这一点,可以通过adb shell登录后,用ps命令查看进程和父进程号来确认。
4.4.3 关于 Zygote分裂的总结
源码分析 — ActivityThread(一)之main()的调用 (Android应用进程的孵化)
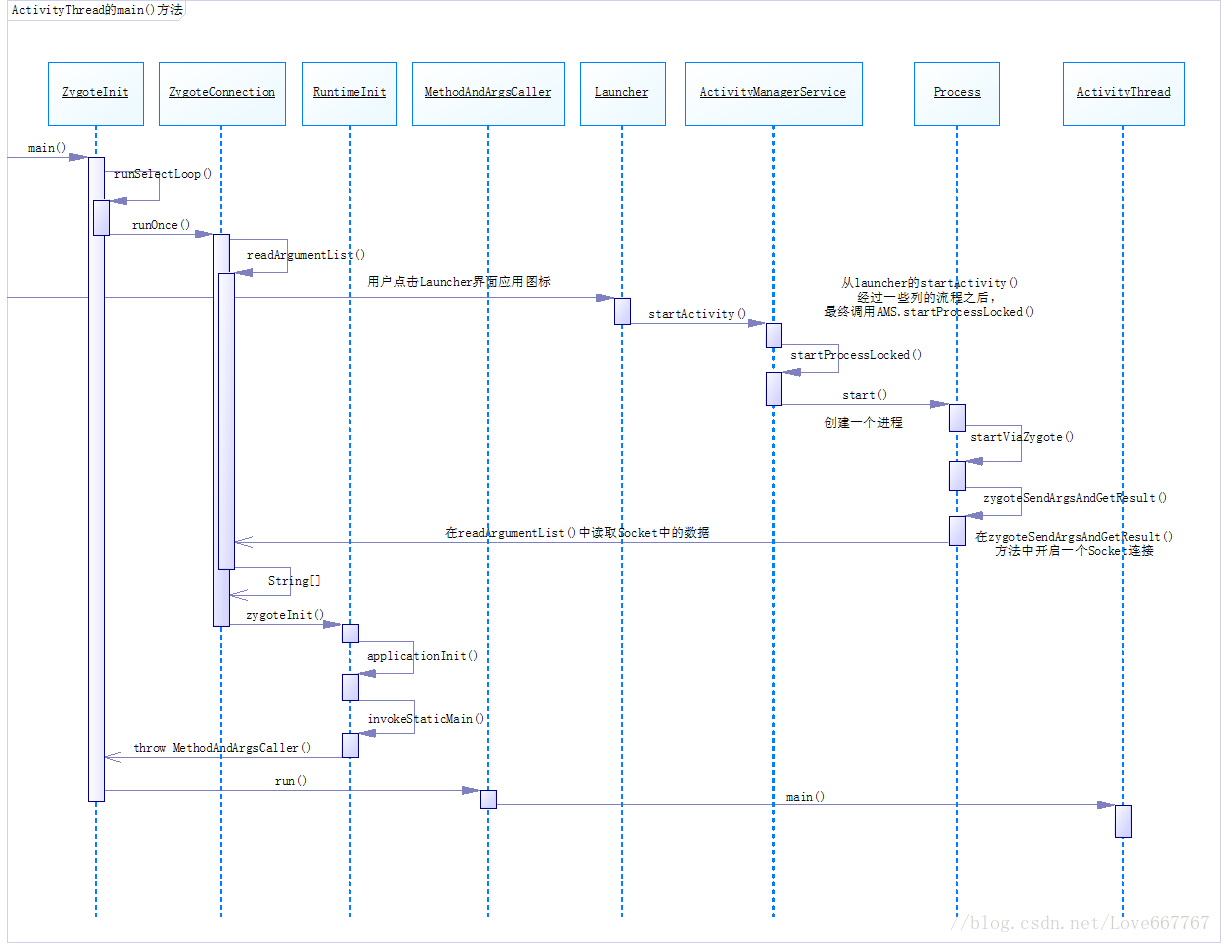
小结: Zygote响应请求的流程
- Zygote 进程调用 ZygoteInit.runSelectLoop() 开启一个轮训器;
- SystemServer 进程发送消息到 Zygote ,在 ZygoteConnection.readArgumentList() 中接收消息;
- Zygote 通过 fork 创建子进程;
- 子进程调用android.app.ActivityThread.main() 方法;
其实,这个原理跟 Handler 的 Looper 原理很像,Looper开启一个轮训器,不断的从 MessageQueue 中获取最新的 Message,进而处理这个消息; 而在 ZygoteInit.runSelectLoop() 也是启动一个轮训器,从指定的 Socket 中读取数据,然后进行处理;