硬件加速绘制
硬件加速绘制
总结:
- CPU更擅长复杂逻辑控制,而GPU得益于大量ALU和并行结构设计,更擅长数学运算。
- 页面由各种基础元素(DisplayList)构成,渲染时需要进行大量浮点运算。
- 硬件加速条件下,CPU用于控制复杂绘制逻辑,构建或更新DisplayList;GPU用于完成图形计算,渲染DisplayList。
- 硬件加速条件下,刷新界面尤其是播放动画时,CPU只重建或更新必要的DisplayList,进一步提高渲染效率。
软硬件加速的区别
软硬件加速的区别主要是==图形的绘制究竟是GPU来处理还是CPU,如果是GPU==,就认为是硬件加速绘制,反之,软件绘制。
不仅仅限定在绘制方面,绘制之前,在如何构建绘制区域上,硬件加速也做出了很大优化,因此硬件加速特性可以从下面两部分来分析:
- ==前期策略:如何构建需要绘制的区域==
- ==后期绘制:单独渲染线程,依赖GPU进行绘制==
无论是软件绘制还是硬件加速,==绘制内存的分配都是类似的,都是需要请求SurfaceFlinger服务分配一块内存==,只不过硬件加速有可能从FrameBuffer硬件缓冲区直接分配内存(SurfaceFlinger一直这么干的),==两者的绘制都是在APP端,绘制完成之后同样需要通知SurfaceFlinger进行合成,在这个流程上没有任何区别==,真正的区别在于在APP端如何完成UI数据绘制
软件绘制同硬件加速的区别主要是在绘制上,内存分配、图层合成等整体流程是一样的,只不过硬件加速相比软件绘制算法更加合理,同时采用单独的渲染线程,减轻了主线程的负担。
软件绘制跟硬件加速的分歧点
ViewRootImpl.java
private void draw(boolean fullRedrawNeeded) {
...
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
//关键点1 是否开启硬件加速
if (mAttachInfo.mHardwareRenderer != null && mAttachInfo.mHardwareRenderer.isEnabled()) {
...
dirty.setEmpty();
mBlockResizeBuffer = false;
//关键点2 硬件加速绘制
mAttachInfo.mHardwareRenderer.draw(mView, mAttachInfo, this);
} else {
...
//关键点3 软件绘制
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset, scalingRequired, dirty)) {
return;
}
...
其实到这里软件绘制跟硬件加速的分歧点已经找到了,就是ViewRootImpl在draw的时候,如果需要硬件加速就利用 HardwareRenderer进行draw,否则走软件绘制流程,drawSoftware其实很简单,利用Surface.lockCanvas,向SurfaceFlinger申请一块匿名共享内存内存分配,同时获取一个普通的SkiaCanvas,用于调用Skia库,进行图形绘制,
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty) {
final Canvas canvas;
try {
//关键点1
canvas = mSurface.lockCanvas(dirty);
..
//关键点2 绘制
mView.draw(canvas);
..
//关键点3 通知SurfaceFlinger进行图层合成
surface.unlockCanvasAndPost(canvas);
} ...
return true; }
默认情况下Skia的绘制没有采用GPU渲染的方式(虽然Skia也能用GPU渲染),也就说默认drawSoftware工作完全由CPU来完成,不会牵扯到GPU的操作,但是8.0之后,Google逐渐加重了Skia,开始让Skia接手OpenGL,间接统一调用,将来还可能是Skia同Vulkan的结合,不过这里不是重点。重点看下HardwareRenderer所进行的硬件加速绘制。
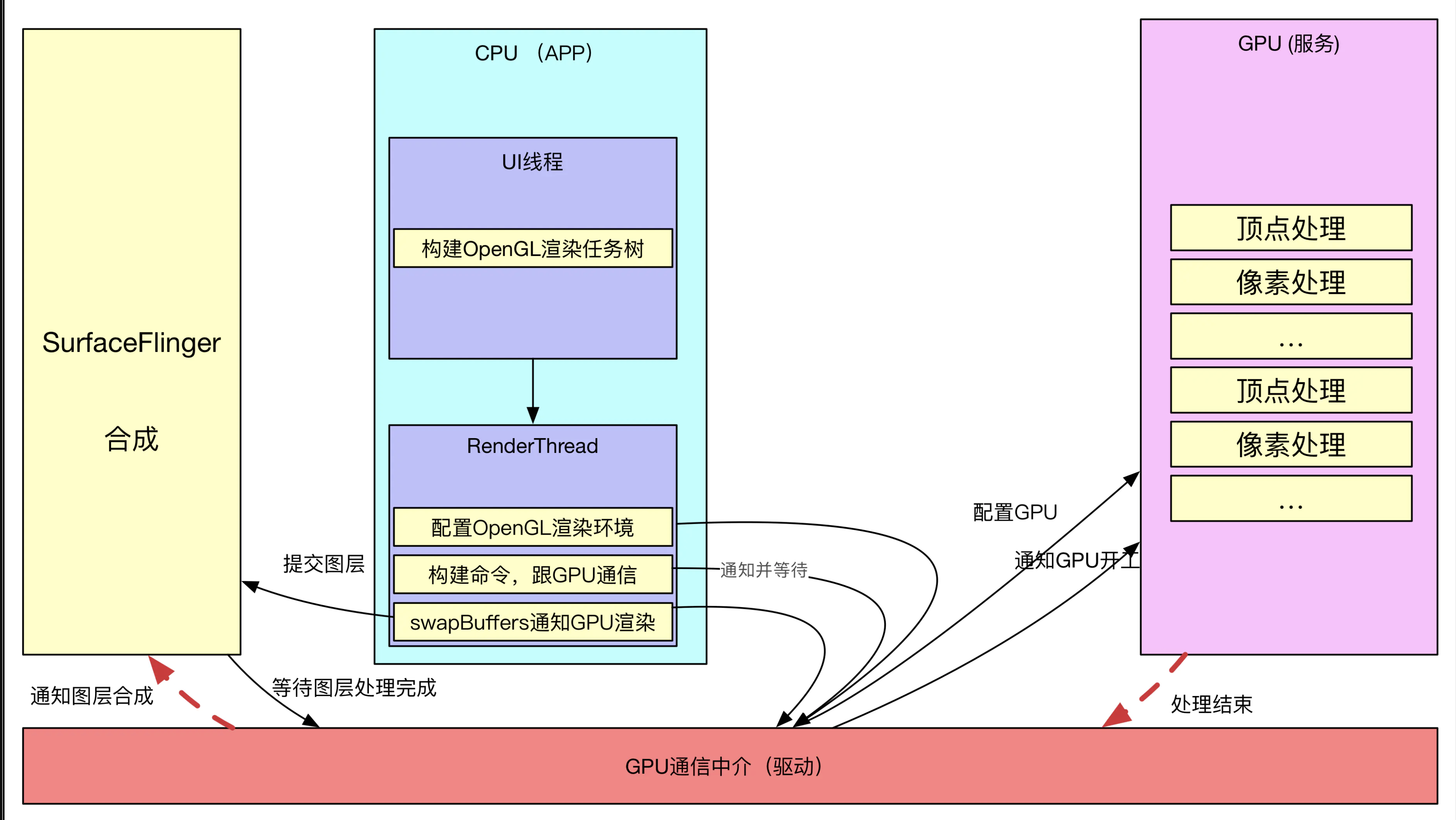
HardwareRenderer硬件加速绘制模型
开头说过,硬件加速绘制包括两个阶段:==构建阶段+绘制阶段==,所谓构建就是递归遍历所有视图,将需要的操作缓存下来,之后再交给单独的Render线程利用OpenGL渲染。在Android硬件加速框架中,==View视图被抽象成RenderNode节点==,==View中的绘制都会被抽象成一个个DrawOp(DisplayListOp)==,比如View中drawLine,构建中就会被抽象成一个DrawLintOp,drawBitmap操作会被抽象成DrawBitmapOp,==每个子View的绘制被抽象成DrawRenderNodeOp,每个DrawOp有对应的OpenGL绘制命令,同时内部也握着绘图所需要的数据==。如下所示:
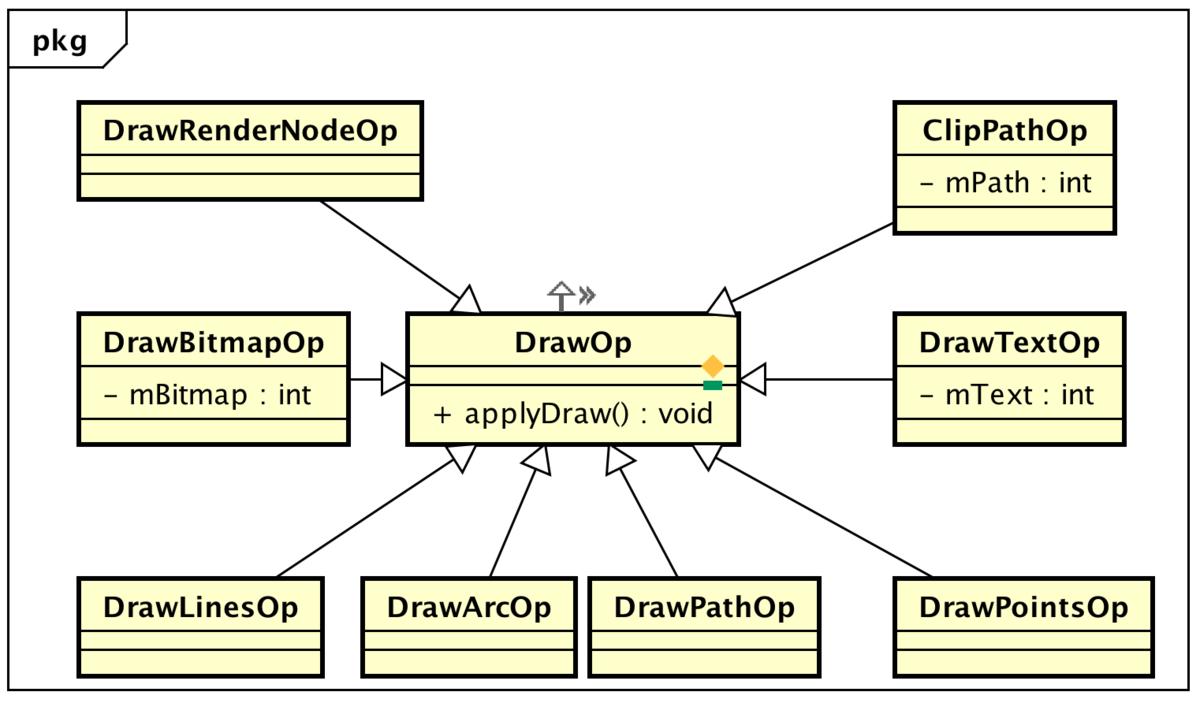
如此以来,==每个View不仅仅握有自己DrawOp List,同时还拿着子View的绘制入口,如此递归==,便能够统计到所有的绘制Op,很多分析都称==为Display List==,源码中也是这么来命名类的,不过这里其实更像是一个树,而不仅仅是List,示意如下:
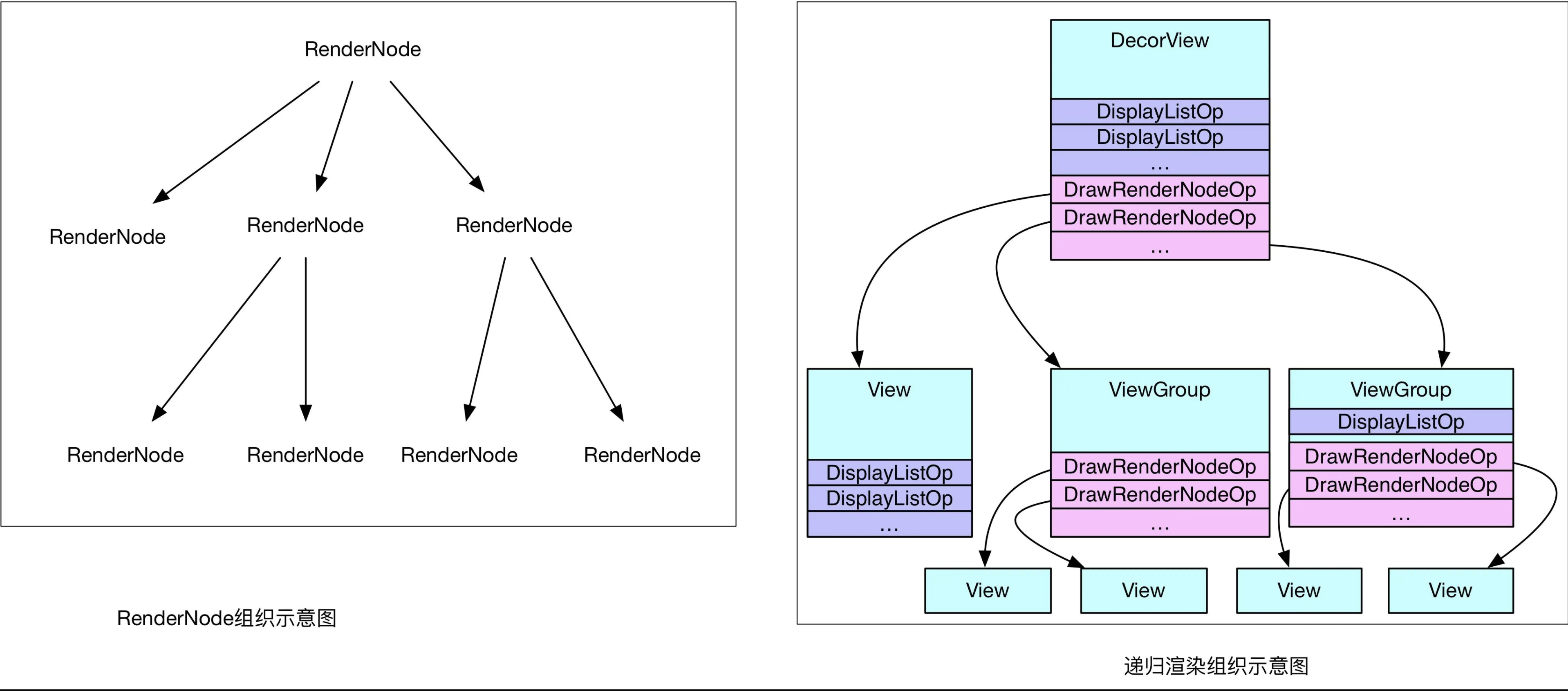
构建完成后,就可以==将这个绘图Op树交给Render线程进行绘制==,这里是同软件绘制很不同的地方,软件绘制时,View一般都在主线程中完成绘制,而硬件加速,除非特殊要求,一般都是在单独线程中完成绘制,如此以来就分担了主线程很多压力,提高了UI线程的响应速度。
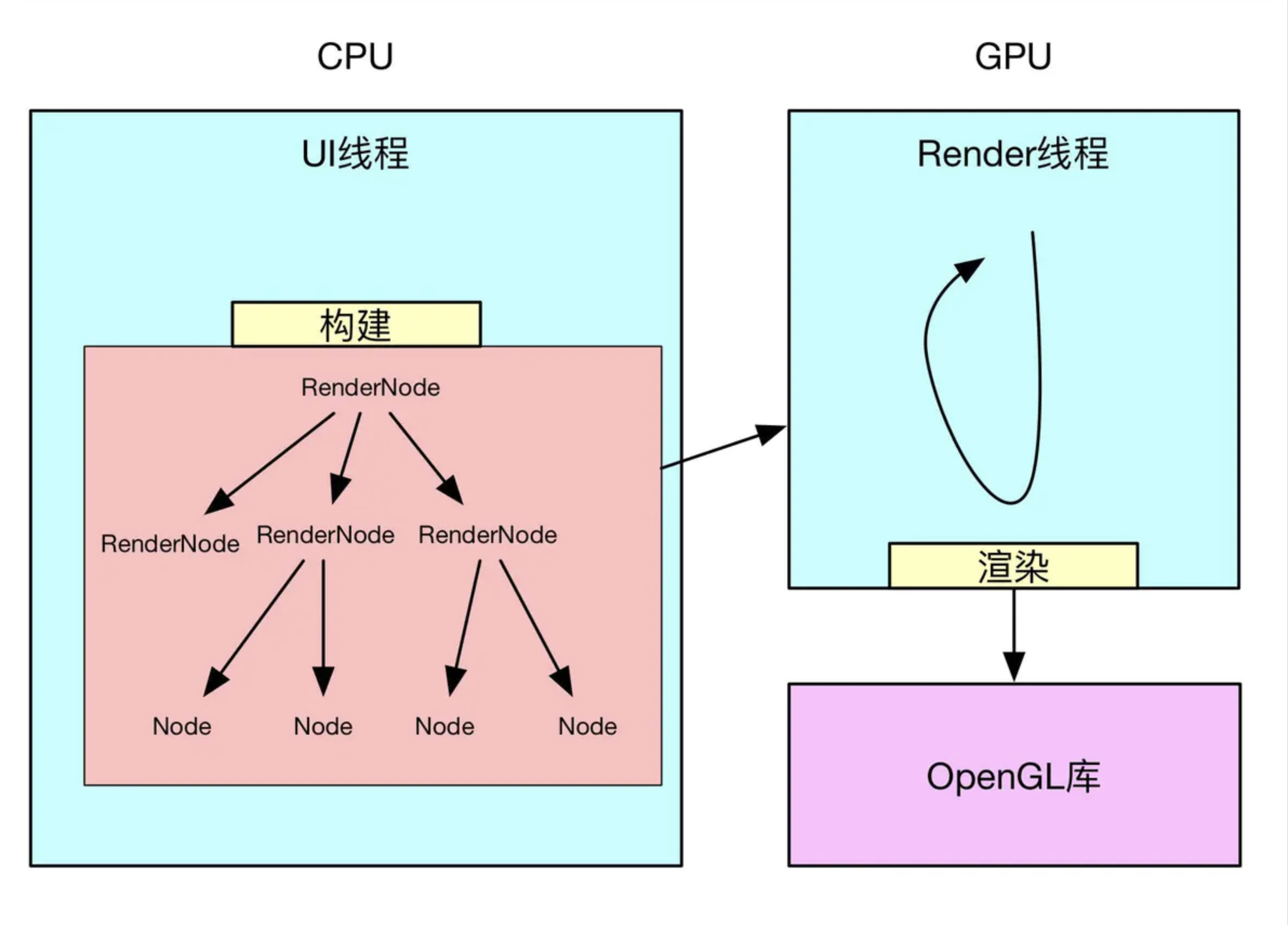
Android硬件加速(二)-RenderThread与OpenGL GPU渲染
利用HardwareRenderer构建DrawOp集
HardwareRenderer是整个硬件加速绘制的入口,实现是一个ThreadedRenderer对象,从名字能看出,ThreadedRenderer应该跟一个Render线程息息相关,不过ThreadedRenderer是在UI线程中创建的,那么与UI线程也必定相关,其主要作用:
- ==在UI线程中完成DrawOp集构建==
- ==负责跟渲染线程通信==
可见ThreadedRenderer的作用是很重要的,简单看一下实现:
ThreadedRenderer(Context context, boolean translucent) {
...
//新建native node
long rootNodePtr = nCreateRootRenderNode();
mRootNode = RenderNode.adopt(rootNodePtr);
mRootNode.setClipToBounds(false);
//新建NativeProxy
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
ProcessInitializer.sInstance.init(context, mNativeProxy);
loadSystemProperties();
}
从上面代码看出,ThreadedRenderer中有一个==RootNode==用来标识整个DrawOp树的根节点,有个这个根节点就可以访问所有的绘制Op,同时还有个==RenderProxy对象,这个对象就是用来跟渲染线程进行通信的句柄==,看一下其构造函数:
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode, IContextFactory* contextFactory)
: mRenderThread(RenderThread::getInstance())
, mContext(nullptr) {
SETUP_TASK(createContext);
args->translucent = translucent;
args->rootRenderNode = rootRenderNode;
args->thread = &mRenderThread;
args->contextFactory = contextFactory;
mContext = (CanvasContext*) postAndWait(task);
mDrawFrameTask.setContext(&mRenderThread, mContext);
}
从RenderThread::getInstance()可以看出,==RenderThread是一个单例线程==,也就是说,每个进程最多只有一个硬件渲染线程,这样就不会存在多线程并发访问冲突问题。下面就接着看ThreadedRenderer的draw函数,如何构建渲染Op树:
ThreadedRenderer::draw
@Override
void draw(View view, AttachInfo attachInfo, HardwareDrawCallbacks callbacks) {
attachInfo.mIgnoreDirtyState = true;
final Choreographer choreographer = attachInfo.mViewRootImpl.mChoreographer;
choreographer.mFrameInfo.markDrawStart();
//关键点1:构建View的DrawOp树
updateRootDisplayList(view, callbacks);
//关键点2:通知RenderThread线程绘制
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
...
}
关键点1 updateRootDisplayList,构建RootDisplayList,其实就是构建View的DrawOp树,==updateRootDisplayList会进而调用根View的updateDisplayListIfDirty,让其递归子View的updateDisplayListIfDirty,从而完成DrawOp树的创==建,简述一下流程:
updateRootDisplayList
private void updateRootDisplayList(View view, HardwareDrawCallbacks callbacks) {
updateViewTreeDisplayList(view);
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
//获取DisplayListCanvas, 利用View的RenderNode获取一个DisplayListCanvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
//利用canvas缓存Op, 利用DisplayListCanvas构建并缓存所有的DrawOp
final int saveCount = canvas.save();
canvas.translate(mInsetLeft, mInsetTop);
callbacks.onHardwarePreDraw(canvas);
canvas.insertReorderBarrier();
canvas.drawRenderNode(view.updateDisplayListIfDirty());
canvas.insertInorderBarrier();
callbacks.onHardwarePostDraw(canvas);
canvas.restoreToCount(saveCount);
mRootNodeNeedsUpdate = false;
} finally {
//将所有Op填充到RootRenderNode, 将DisplayListCanvas缓存的DrawOp填充到RenderNode
mRootNode.end(canvas);
}
}
}
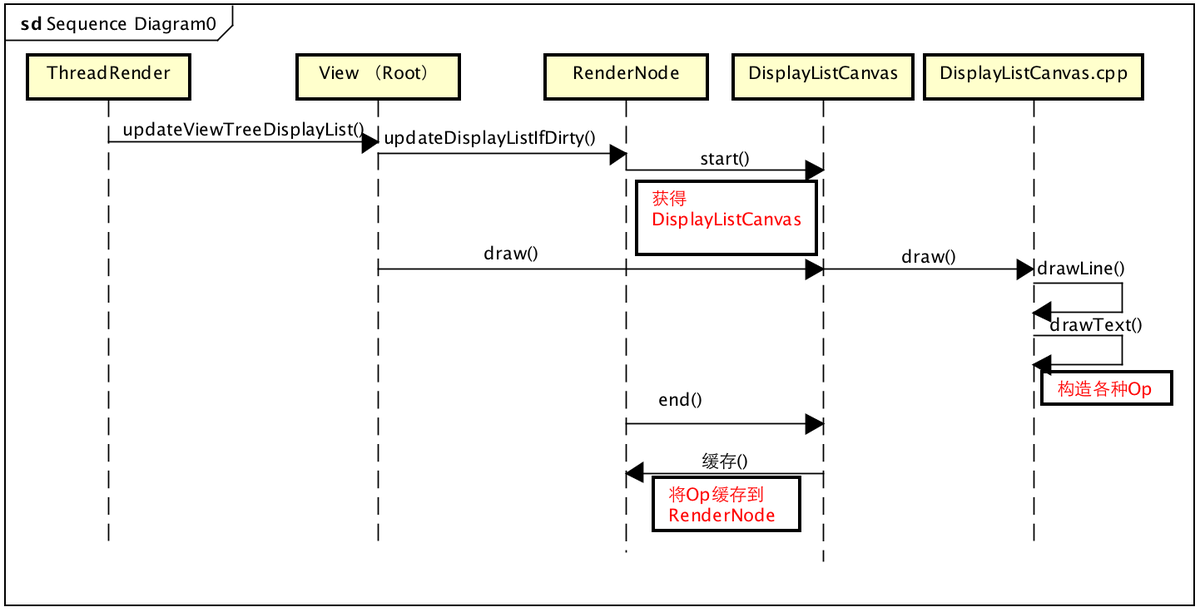
View.java递归构建DrawOp
@NonNull
public RenderNode updateDisplayListIfDirty() {
final RenderNode renderNode = mRenderNode;
...
// start 获取一个 DisplayListCanvas 用于绘制 硬件加速
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
// 是否是textureView
final HardwareLayer layer = getHardwareLayer();
if (layer != null && layer.isValid()) {
canvas.drawHardwareLayer(layer, 0, 0, mLayerPaint);
} else if (layerType == LAYER_TYPE_SOFTWARE) {
// 是否强制软件绘制
buildDrawingCache(true);
Bitmap cache = getDrawingCache(true);
if (cache != null) {
canvas.drawBitmap(cache, 0, 0, mLayerPaint);
}
} else {
// 如果仅仅是ViewGroup,并且自身不用绘制,直接递归子View
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
dispatchDraw(canvas);
} else {
//调用自己draw,如果是ViewGroup会递归子View
draw(canvas);
}
}
} finally {
//缓存构建Op
renderNode.end(canvas);
setDisplayListProperties(renderNode);
}
}
return renderNode;
}
ViewGroup::dispatchDraw
@Override
protected void dispatchDraw(Canvas canvas) {
boolean usingRenderNodeProperties = canvas.isRecordingFor(mRenderNode);
final int childrenCount = mChildrenCount;
final View[] children = mChildren;
int flags = mGroupFlags;
for (int i = 0; i < childrenCount; i++) {
final int childIndex = getAndVerifyPreorderedIndex(childrenCount, i, customOrder);
final View child = getAndVerifyPreorderedView(preorderedList, children, childIndex);
if ((child.mViewFlags & VISIBILITY_MASK) == VISIBLE || child.getAnimation() != null) {
more |= drawChild(canvas, child, drawingTime);
}
}
}
protected boolean drawChild(Canvas canvas, View child, long drawingTime) {
return child.draw(canvas, this, drawingTime);
}
View::draw
boolean draw(Canvas canvas, ViewGroup parent, long drawingTime) {
boolean drawingWithRenderNode = mAttachInfo != null
&& mAttachInfo.mHardwareAccelerated
&& hardwareAcceleratedCanvas;
if (drawingWithRenderNode) {
renderNode = updateDisplayListIfDirty();
}
}
drawLine
假如在View onDraw中,有个drawLine,这里就会调用DisplayListCanvas的drawLine函数,DisplayListCanvas及RenderNode类图大概如下
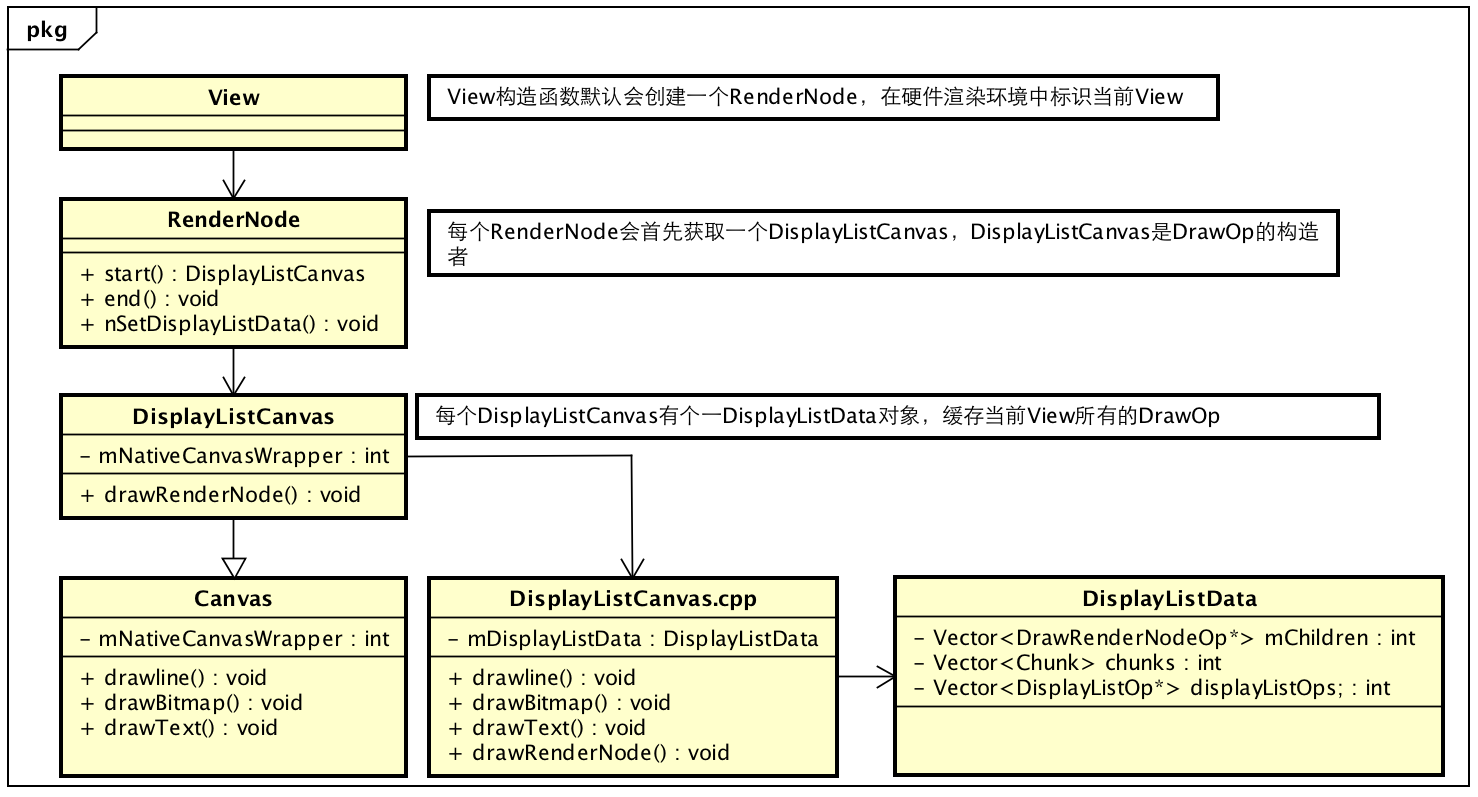
DisplayListCanvas的drawLine函数最终会进入DisplayListCanvas.cpp的drawLine,
void DisplayListCanvas::drawLines(const float* points, int count, const SkPaint& paint) {
points = refBuffer<float>(points, count);
addDrawOp(new (alloc()) DrawLinesOp(points, count, refPaint(&paint)));
}
可以看到,这里构建了一个DrawLinesOp,并添加到DisplayListCanvas的缓存列表中去,如此递归便可以完成DrawOp树的构建,在构建后利用RenderNode的end函数,将DisplayListCanvas中的数据缓存到RenderNode中去:
public void end(DisplayListCanvas canvas) {
canvas.onPostDraw();
long renderNodeData = canvas.finishRecording();
//将DrawOp缓存到RenderNode中去
nSetDisplayListData(mNativeRenderNode, renderNodeData);
// canvas 回收掉]
canvas.recycle();
mValid = true;
}
RenderThread渲染UI到Graphic Buffer
DrawOp树构建完毕后,UI线程利用RenderProxy向RenderThread线程发送一个DrawFrameTask任务请求,RenderThread被唤醒,开始渲染,大致流程如下:
- 首先进行DrawOp的==合并==
- 接着绘制特殊的Layer
- 最后==绘制其余所有的DrawOpList==
- 调用swapBuffers将前面已经绘制好的图形缓冲区提交给Surface Flinger合成和显示。
syncAndDrawFrame
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
return proxy->syncAndDrawFrame();
}
RenderProxy::syncAndDrawFrame
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}
DrawFrameTask::drawFrame
int DrawFrameTask::drawFrame() {
postAndWait();
return mSyncResult;
}
DrawFrameTask::postAndWait
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
mRenderThread->queue().post([this]() { run(); });
mSignal.wait(mLock);
}
DrawFrameTask::run
void DrawFrameTask::run() {
canUnblockUiThread = syncFrameState(info);
// Grab a copy of everything we need
CanvasContext* context = mContext;
// From this point on anything in "this" is *UNSAFE TO ACCESS*
if (canUnblockUiThread) {
unblockUiThread();
}
if (CC_LIKELY(canDrawThisFrame)) {
context->draw();
} else {
// wait on fences so tasks don't overlap next frame
context->waitOnFences();
}
if (!canUnblockUiThread) {
unblockUiThread();
}
}
CanvasContext::draw
void CanvasContext::draw() {
mCurrentFrameInfo->markIssueDrawCommandsStart();
Frame frame = mRenderPipeline->getFrame();
SkRect windowDirty = computeDirtyRect(frame, &dirty);
bool drew = mRenderPipeline->draw(frame, windowDirty, dirty, mLightGeometry, &mLayerUpdateQueue,
mContentDrawBounds, mOpaque, mWideColorGamut, mLightInfo,
mRenderNodes, &(profiler()));
bool didSwap =
mRenderPipeline->swapBuffers(frame, drew, windowDirty, mCurrentFrameInfo, &requireSwap);
}
绘制内存的由来
DrawOp树的构建只是在普通的==用户内存==中,而部分数据对于SurfaceFlinger都是不可见的,之后又绘制到==共享内存==中的数据才会被SurfaceFlinger合成,之前分析过软件绘制的共享内存是来自匿名共享内存,那么硬件加速的共享内存来自何处呢?到这里可能要倒回去看看ViewRootImpl
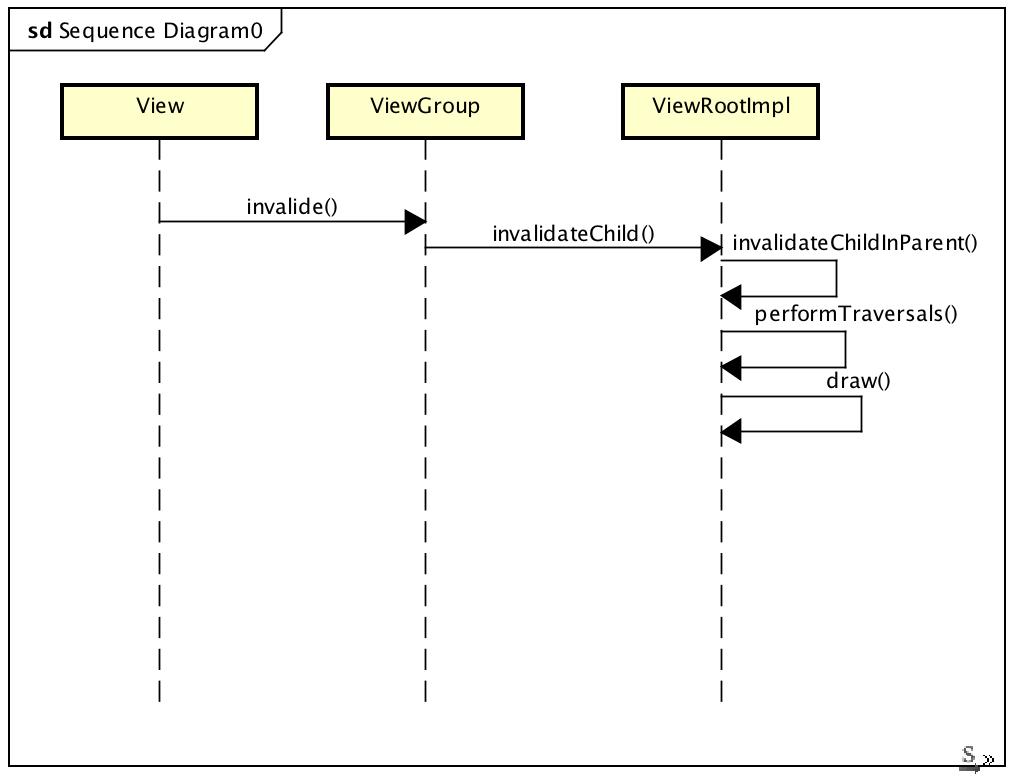
private void performTraversals() {
...
if (mAttachInfo.mHardwareRenderer != null) {
try {
hwInitialized = mAttachInfo.mHardwareRenderer.initialize(mSurface);
if (hwInitialized && (host.mPrivateFlags
& View.PFLAG_REQUEST_TRANSPARENT_REGIONS) == 0) {
mSurface.allocateBuffers();
}
} catch (OutOfResourcesException e) {
handleOutOfResourcesException(e);
return;
}
}
....
/**
* Allocate buffers ahead of time to avoid allocation delays during rendering
* @hide
*/
public void allocateBuffers() {
synchronized (mLock) {
checkNotReleasedLocked();
nativeAllocateBuffers(mNativeObject);
}
}
frameworks/native/libs/gui/include/gui/Surface.h
/* Allocates buffers based on the current dimensions/format.*/
void allocateBuffers();
frameworks/native/libs/gui/Surface.cpp
void Surface::allocateBuffers() {
uint32_t reqWidth = mReqWidth ? mReqWidth : mUserWidth;
uint32_t reqHeight = mReqHeight ? mReqHeight : mUserHeight;
mGraphicBufferProducer->allocateBuffers(reqWidth, reqHeight,
mReqFormat, mReqUsage);
}
frameworks/native/libs/gui/include/gui/IGraphicBufferProducer.h
// Allocates buffers based on the given dimensions/format.
//
// This function will allocate up to the maximum number of buffers
// permitted by the current BufferQueue configuration. It will use the
// given format, dimensions, and usage bits, which are interpreted in the
// same way as for dequeueBuffer, and the async flag must be set the same
// way as for dequeueBuffer to ensure that the correct number of buffers are
// allocated. This is most useful to avoid an allocation delay during
// dequeueBuffer. If there are already the maximum number of buffers
// allocated, this function has no effect.
virtual void allocateBuffers(uint32_t width, uint32_t height,
PixelFormat format, uint64_t usage) = 0;
BufferQueueCore相关属性定义
frameworks/native/libs/gui/include/gui/BufferQueueCore.h
// mSlots is an array of buffer slots that must be mirrored on the producer
// side. This allows buffer ownership to be transferred between the producer
// and consumer without sending a GraphicBuffer over Binder. The entire
// array is initialized to NULL at construction time, and buffers are
// allocated for a slot when requestBuffer is called with that slot's index.
BufferQueueDefs::SlotsType mSlots;
// mQueue is a FIFO of queued buffers used in synchronous mode.
Fifo mQueue;
// mFreeSlots contains all of the slots which are FREE and do not currently
// have a buffer attached.
std::set<int> mFreeSlots;
// mFreeBuffers contains all of the slots which are FREE and currently have
// a buffer attached.
std::list<int> mFreeBuffers;
frameworks/native/libs/gui/include/gui/BufferQueueDefs.h
namespace BufferQueueDefs {
typedef BufferSlot SlotsType[NUM_BUFFER_SLOTS];
} // namespace BufferQueueDefs
frameworks/native/libs/ui/include/ui/BufferQueueDefs.h
namespace BufferQueueDefs {
// BufferQueue will keep track of at most this value of buffers.
// Attempts at runtime to increase the number of buffers past this
// will fail.
static constexpr int NUM_BUFFER_SLOTS = 64;
} // namespace BufferQueueDefs
frameworks/native/libs/gui/include/gui/Surface.h
struct BufferSlot {
sp<GraphicBuffer> buffer;
Region dirtyRegion;
};
对于硬件加速的场景,请求SurfaceFlinger内存分配的时机会稍微提前,而不是像软件绘制,由Surface的lockCanvas发起,主要目的是:预先分配slot位置,避免在渲染的时候再申请,一是避免分配失败,浪费了CPU之前的准备工作,二是也可以将渲染线程个工作简化,减少延时。不过,还是会存在另一个问题,一个APP进程,==同一时刻会有多个Surface绘图界面,但是渲染线程只有一个,那么究竟渲染那个呢==?这个时候就需要将Surface与渲染线程(上下文)绑定。
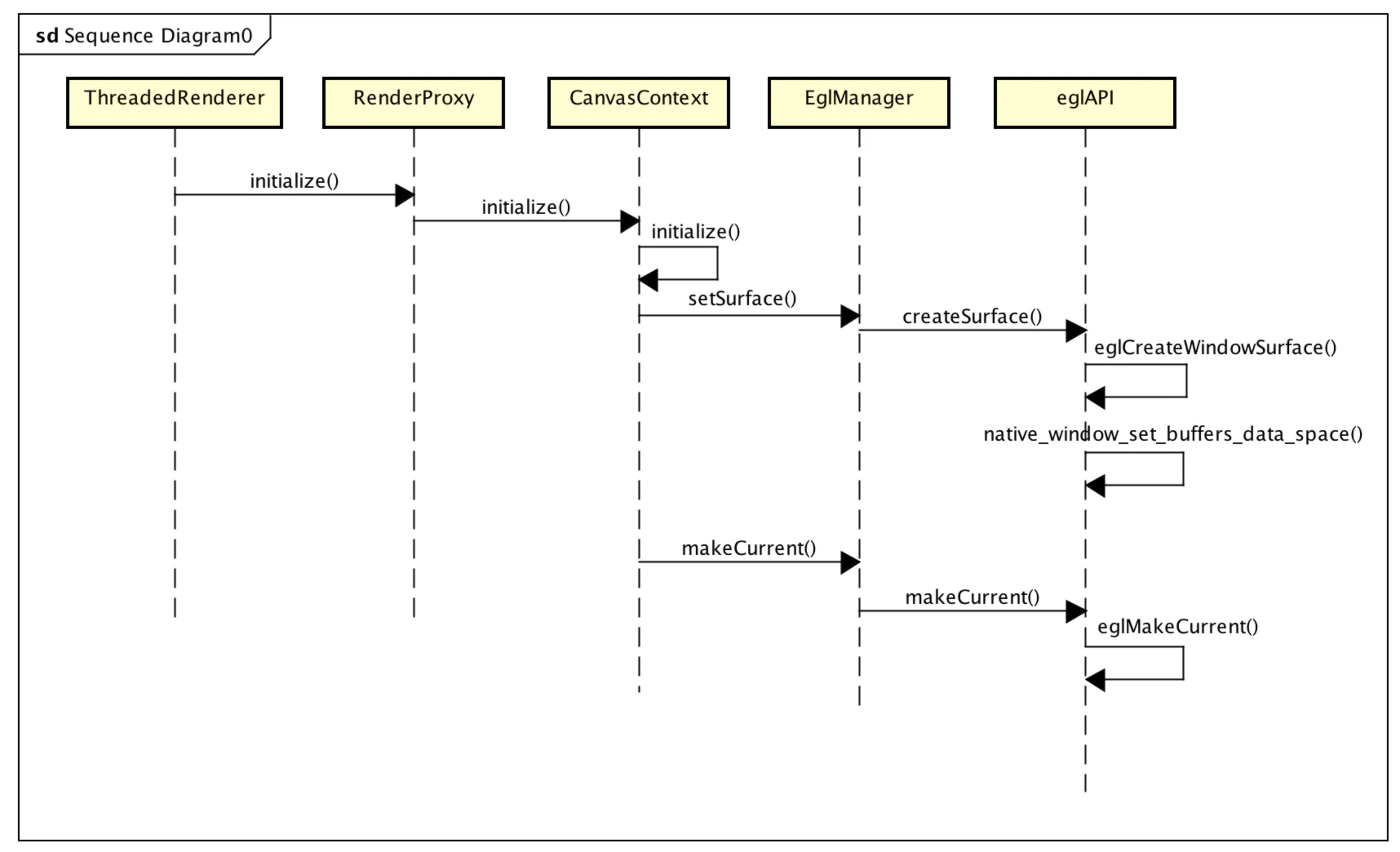
Surface与渲染线程(上下文)绑定
static jboolean android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
sp<ANativeWindow> window = android_view_Surface_getNativeWindow(env, jsurface);
return proxy->initialize(window);
}
首先通过android_view_Surface_getNativeWindowSurface获取Surface,在Native层,Surface对应一个ANativeWindow,接着,通过RenderProxy类的成员函数initialize将前面获得的ANativeWindow绑定到RenderThread
bool RenderProxy::initialize(const sp<ANativeWindow>& window) {
SETUP_TASK(initialize);
args->context = mContext;
args->window = window.get();
return (bool) postAndWait(task);
}
仍旧是向渲染线程发送消息,让其绑定当前Window,其实就是调用CanvasContext的initialize函数,让绘图上下文绑定绘图内存:
bool CanvasContext::initialize(ANativeWindow* window) {
setSurface(window);//main
if (mCanvas) return false;
mCanvas = new OpenGLRenderer(mRenderThread.renderState());
mCanvas->initProperties();
return true;
}
CanvasContext通过setSurface将当前要渲染的Surface绑定到到RenderThread中,大概流程是通过eglApi获得一个EGLSurface,EGLSurface封装了一个绘图表面,进而,==通过eglApi将EGLSurface设定为当前渲染窗口==,并将绘图内存等信息进行同步,==之后通过RenderThread绘制的时候才能知道是在哪个窗口上进行绘制==。之后,再创建一个OpenGLRenderer对象,后面执行OpenGL相关操作的时候,其实就是通过OpenGLRenderer来进行的。
合并操作和绘制
真正调用OpenGL绘制之前还有一些合并操作,这是Android硬件加速做的优化,回过头继续走draw流程,其实就是走OpenGLRenderer的drawRenderNode进行递归处理:
void OpenGLRenderer::drawRenderNode(RenderNode* renderNode, Rect& dirty, int32_t replayFlags) {
...
<!--构建deferredList-->
DeferredDisplayList deferredList(mState.currentClipRect(), avoidOverdraw);
DeferStateStruct deferStruct(deferredList, *this, replayFlags);
<!--合并及分组-->
renderNode->defer(deferStruct, 0);
<!--绘制layer-->
flushLayers();
startFrame();
<!--绘制 DrawOp树-->
deferredList.flush(*this, dirty);
...
}
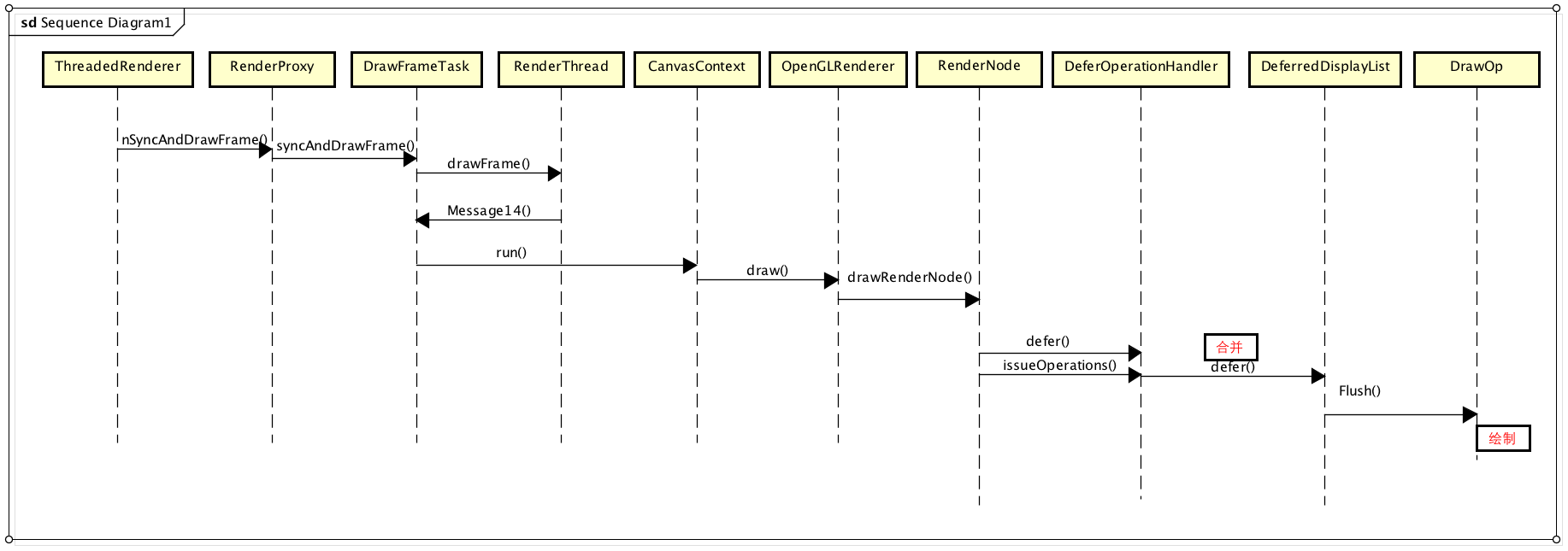
先看下renderNode->defer(deferStruct, 0),合并操作,DrawOp树并不是直接被绘制的,而是首先通过DeferredDisplayList进行一个合并优化,这个是Android硬件加速中采用的一种优化手段,不仅可以减少不必要的绘制,还可以将相似的绘制集中处理,提高绘制速度。
void RenderNode::defer(DeferStateStruct& deferStruct, const int level) {
DeferOperationHandler handler(deferStruct, level);
issueOperations<DeferOperationHandler>(deferStruct.mRenderer, handler);
}
RenderNode::defer其实内含递归操作,比如,如果当前RenderNode代表DecorView,它就会递归所有的子View进行合并优化处理
合并及优化的流程及算法,其实主要就是根据DrawOp树构建DeferedDisplayList。在合并过程中,DrawOp被分为两种:需要合的与不需要合并的,并分别缓存在不同的列表中,
- 无法合并的按照类型分别存放在Batch*mBatchLookup[kOpBatch_Count]中
- 可以合并的按照类型及MergeID存储到TinyHashMap<mergeid_t, DrawBatch*>mMergingBatches[kOpBatch_Count]中
合并之后,DeferredDisplayList Vector<Batch * > mBatches 包含全部整合后的绘制命令,之后渲染即可,需要注意的是这里的合并并不是多个变一个,只是做了一个集合,主要是方便使用各资源纹理等,比如绘制文字的时候,需要根据文字的纹理进行渲染,而这个时候就需要查询文字的纹理坐标系,合并到一起方便统一处理,一次渲染,减少资源加载的浪费。
它的主要特点是==在另一个Render线程使用OpenGL进行绘制==,这个是它最重要的特点。而mBatches中所有的DrawOp都会通过OpenGL被绘制到GraphicBuffer中,最后通过swapBuffers通知SurfaceFlinger合成。
frameworks/base/libs/hwui/renderthread/OpenGLPipeline.cpp
OpenGLPipeline.swapBuffers
bool OpenGLPipeline::swapBuffers(const Frame& frame, bool drew, const SkRect& screenDirty,
FrameInfo* currentFrameInfo, bool* requireSwap) {
......
if (*requireSwap && (CC_UNLIKELY(!mEglManager.swapBuffers(frame, screenDirty)))) {
return false;
}
return *requireSwap;
}