4BinderKernel
图解binder_ioctl
graph TB
binder_ioctl-->|case BINDER_WRITE_READ|binder_ioctl_write_read
binder_ioctl_write_read-->copy_from_user("copy_from_user(&bwr, ubuf, sizeof(bwr));")
binder_ioctl_write_read-->|bwr.write_size > 0|binder_thread_write
binder_ioctl_write_read-->|bwr.read_size > 0|binder_thread_read
binder_ioctl_write_read-->copy_to_user("copy_to_user(ubuf, &bwr, sizeof(bwr))")
binder_thread_write-->|拷贝用户空间的cmd命令|get_user("get_user(cmd, (uint32_t __user *)ptr)")-->|case BC_TRANSACTION:拷贝用户空间的binder_transaction_data|binder_transaction("binder_transaction(proc, thread, &tr,cmd == BC_REPLY, 0)")-->|handle=0则找到servicemanager实体|service_manager("context->binder_context_mgr_node")
subgraph 得到binder_node->proc,也就是binder_proc*类型的target_proc
binder_get_node_refs_for_txn
end
subgraph open系统调用时返回的fd信息的private_data里是binder_proc,而mmap过程会修改这个binder_proc的alloc字段信息,从而确保申请的内存位于target process对应的内核空间
binder_alloc_new_buf
end
service_manager-->binder_get_node_refs_for_txn("binder_get_node_refs_for_txn(target_node, &target_proc,&return_error);")
subgraph 从rbTree中找到ref->data.desc等于入参handle的binder_ref将其返回
binder_get_ref_olocked
end
binder_transaction-->|target.handle > 0|binder_get_ref_olocked("binder_get_ref_olocked(proc, tr->target.handle,true)")
binder_get_ref_olocked-->|传递ref->node作为binder_node参数|binder_get_node_refs_for_txn
binder_get_node_refs_for_txn-->binder_alloc_new_buf("t->buffer = binder_alloc_new_buf(&target_proc->alloc,...")
subgraph queues a transaction to binder_proc, find a thread in binder_proc to handle the transaction and wake it up. If no thread is found, the work is queued to the proc waitqueue.
subgraph If the thread parameter is not NULL, the transaction is always queued to the waitlist of that specific thread.
binder_proc_transaction
end
end
binder_alloc_new_buf-->binder_proc_transaction("binder_proc_transaction(struct binder_transaction *t, struct binder_proc *proc,struct binder_thread *thread)")
subgraph Linux系统API
wake_up_interruptible
end
binder_proc_transaction-->wake_up_interruptible
binder_write_read
struct binder_write_read {
binder_size_t write_size; /* bytes to write */
binder_size_t write_consumed; /* bytes consumed by driver */
binder_uintptr_t write_buffer;
binder_size_t read_size; /* bytes to read */
binder_size_t read_consumed; /* bytes consumed by driver */
binder_uintptr_t read_buffer;
};
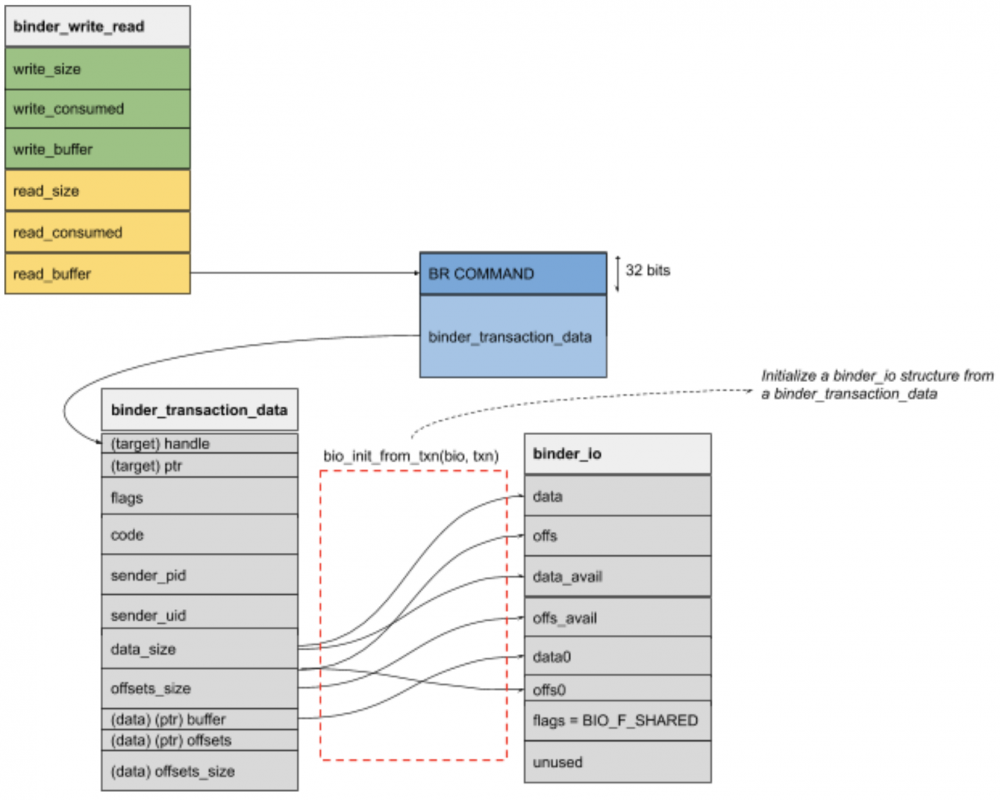
binder_transaction_data
struct binder_transaction_data {
/* The first two are only used for bcTRANSACTION and brTRANSACTION,
* identifying the target and contents of the transaction.
*/
union {
/* target descriptor of command transaction */
__u32 handle;
/* target descriptor of return transaction */
binder_uintptr_t ptr;
} target;
binder_uintptr_t cookie; /* target object cookie */
__u32 code; /* transaction command */
/* General information about the transaction. */
__u32 flags;
pid_t sender_pid;
uid_t sender_euid;
binder_size_t data_size; /* number of bytes of data */
binder_size_t offsets_size; /* number of bytes of offsets */
/* If this transaction is inline, the data immediately
* follows here; otherwise, it ends with a pointer to
* the data buffer.
*/
union {
struct {
/* transaction data */
binder_uintptr_t buffer;
/* offsets from buffer to flat_binder_object structs */
binder_uintptr_t offsets;
} ptr;
__u8 buf[8];
} data;
};
drivers/android/binder.c
binder.c
binder_ioctl
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
int ret;
struct binder_proc *proc = filp->private_data;
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
}
}
binder_ioctl_write_read
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
//将用户空间bwr结构体拷贝到内核空间
copy_from_user(&bwr, ubuf, sizeof(bwr));
binder_debug(BINDER_DEBUG_READ_WRITE,
"%d:%d write %lld at %016llx, read %lld at %016llx\n",
proc->pid, thread->pid,
(u64)bwr.write_size, (u64)bwr.write_buffer,
(u64)bwr.read_size, (u64)bwr.read_buffer);
if (bwr.write_size > 0) {
//将数据放入目标进程
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
}
if (bwr.read_size > 0) {
//读取自己队列的数据
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
}
//将内核空间bwr结构体拷贝到用户空间
copy_to_user(ubuf, &bwr, sizeof(bwr))
return ret;
}
binder_thread_write
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error.cmd == BR_OK) {
if (get_user(cmd, (uint32_t __user *)ptr))////拷贝用户空间的cmd命令,此时为BC_TRANSACTION
return -EFAULT;
ptr += sizeof(uint32_t);
switch (cmd) {
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
//拷贝用户空间的binder_transaction_data
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
}
binder_transaction
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
struct binder_proc *target_proc = NULL;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
if (reply) {
......
} else {
if (tr->target.handle) {
struct binder_ref *ref;
binder_proc_lock(proc);
ref = binder_get_ref_olocked(proc, tr->target.handle,
true);
if (ref) {
target_node = binder_get_node_refs_for_txn(
ref->node, &target_proc,
&return_error);
} else {
binder_user_error("%d:%d got transaction to invalid handle\n",proc->pid, thread->pid);......
}
binder_proc_unlock(proc);
} else { // handle=0则找到servicemanager实体
mutex_lock(&context->context_mgr_node_lock);
target_node = context->binder_context_mgr_node;
if (target_node)
target_node = binder_get_node_refs_for_txn(
target_node, &target_proc,
&return_error);
else
return_error = BR_DEAD_REPLY;
mutex_unlock(&context->context_mgr_node_lock);
}
t->buffer = binder_alloc_new_buf(&target_proc->alloc, tr->data_size,
tr->offsets_size, extra_buffers_size, !reply && (t->flags & TF_ONE_WAY));
......
if (reply) {
......
} else if (!(t->flags & TF_ONE_WAY)) {
BUG_ON(t->buffer->async_transaction != 0);
/*
* Defer the TRANSACTION_COMPLETE, so we don't return to
* userspace immediately; this allows the target process to
* immediately start processing this transaction, reducing
* latency. We will then return the TRANSACTION_COMPLETE when
* the target replies (or there is an error).
*/
binder_enqueue_deferred_thread_work_ilocked(thread, tcomplete);
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
if (!binder_proc_transaction(t, target_proc, target_thread)) {
......
goto err_dead_proc_or_thread;
}
} else {
BUG_ON(target_node == NULL);
BUG_ON(t->buffer->async_transaction != 1);
binder_enqueue_thread_work(thread, tcomplete);
if (!binder_proc_transaction(t, target_proc, NULL))
goto err_dead_proc_or_thread;
}
binder_alloc_new_buf
/**
* binder_alloc_new_buf() - Allocate a new binder buffer
* @alloc: binder_alloc for this proc
* @data_size: size of user data buffer
* @offsets_size: user specified buffer offset
* @extra_buffers_size: size of extra space for meta-data (eg, security context)
* @is_async: buffer for async transaction
*
* Allocate a new buffer given the requested sizes. Returns
* the kernel version of the buffer pointer. The size allocated
* is the sum of the three given sizes (each rounded up to
* pointer-sized boundary)
*
* Return: The allocated buffer or %NULL if error
*/
struct binder_buffer *binder_alloc_new_buf(struct binder_alloc *alloc,
size_t data_size,
size_t offsets_size,
size_t extra_buffers_size,
int is_async)
{
struct binder_buffer *buffer;
mutex_lock(&alloc->mutex);
buffer = binder_alloc_new_buf_locked(alloc, data_size, offsets_size,
extra_buffers_size, is_async);
mutex_unlock(&alloc->mutex);
return buffer;
}
binder_get_ref_olocked
static struct binder_ref *binder_get_ref_olocked(struct binder_proc *proc,
u32 desc, bool need_strong_ref)
{
struct rb_node *n = proc->refs_by_desc.rb_node;
struct binder_ref *ref;
while (n) {
ref = rb_entry(n, struct binder_ref, rb_node_desc);
if (desc < ref->data.desc) {
n = n->rb_left;
} else if (desc > ref->data.desc) {
n = n->rb_right;
} else if (need_strong_ref && !ref->data.strong) {
binder_user_error("tried to use weak ref as strong ref\n");
return NULL;
} else {
return ref;
}
}
return NULL;
}
binder_get_node_refs_for_txn
/** Return: The target_node with refs taken or NULL if no @node->proc is NULL.
* Also sets @proc if valid. If the @node->proc is NULL indicating that the
* target proc has died, @error is set to BR_DEAD_REPLY
*/
static struct binder_node *binder_get_node_refs_for_txn(
struct binder_node *node,
struct binder_proc **procp,
uint32_t *error)
{
struct binder_node *target_node = NULL;
binder_node_inner_lock(node);
if (node->proc) {
target_node = node;
binder_inc_node_nilocked(node, 1, 0, NULL);
binder_inc_node_tmpref_ilocked(node);
node->proc->tmp_ref++;
*procp = node->proc;
} else
*error = BR_DEAD_REPLY;
binder_node_inner_unlock(node);
return target_node;
}
struct binder_ref
struct binder_ref {
/* Lookups needed: */
/* node + proc => ref (transaction) */
/* desc + proc => ref (transaction, inc/dec ref) */
/* node => refs + procs (proc exit) */
struct binder_ref_data data;
struct rb_node rb_node_desc;
struct rb_node rb_node_node;
struct hlist_node node_entry;
struct binder_proc *proc;
struct binder_node *node;
struct binder_ref_death *death;
};
binder_proc_transaction
/**
* binder_proc_transaction() - sends a transaction to a process and wakes it up
* @t: transaction to send
* @proc: process to send the transaction to
* @thread: thread in @proc to send the transaction to (may be NULL)
*
* This function queues a transaction to the specified process. It will try
* to find a thread in the target process to handle the transaction and
* wake it up. If no thread is found, the work is queued to the proc
* waitqueue.
*
* If the @thread parameter is not NULL, the transaction is always queued
* to the waitlist of that specific thread.
*
* Return: true if the transactions was successfully queued
* false if the target process or thread is dead
*/
static bool binder_proc_transaction(struct binder_transaction *t,
struct binder_proc *proc,
struct binder_thread *thread)
{
struct binder_node *node = t->buffer->target_node;
struct binder_priority node_prio;
bool oneway = !!(t->flags & TF_ONE_WAY);
bool pending_async = false;
if (oneway) {
BUG_ON(thread);
if (node->has_async_transaction) {
pending_async = true;
} else {
node->has_async_transaction = 1;
}
}
if (!thread && !pending_async)
thread = binder_select_thread_ilocked(proc);
if (thread) {
binder_transaction_priority(thread->task, t, node_prio,
node->inherit_rt);
binder_enqueue_thread_work_ilocked(thread, &t->work);
} else if (!pending_async) {
binder_enqueue_work_ilocked(&t->work, &proc->todo);
} else {
binder_enqueue_work_ilocked(&t->work, &node->async_todo);
}
if (!pending_async)
binder_wakeup_thread_ilocked(proc, thread, !oneway /* sync */);
return true;
}
binder_wakeup_thread_ilocked
/**
* binder_wakeup_thread_ilocked() - wakes up a thread for doing proc work.
* @proc: process to wake up a thread in
* @thread: specific thread to wake-up (may be NULL)
* @sync: whether to do a synchronous wake-up
*
* This function wakes up a thread in the @proc process.
* The caller may provide a specific thread to wake-up in
* the @thread parameter. If @thread is NULL, this function
* will wake up threads that have called poll().
*
* Note that for this function to work as expected, callers
* should first call binder_select_thread() to find a thread
* to handle the work (if they don't have a thread already),
* and pass the result into the @thread parameter.
*/
static void binder_wakeup_thread_ilocked(struct binder_proc *proc,
struct binder_thread *thread,
bool sync)
{
assert_spin_locked(&proc->inner_lock);
if (thread) {
if (sync)
wake_up_interruptible_sync(&thread->wait);
else
wake_up_interruptible(&thread->wait);
return;
}
/* Didn't find a thread waiting for proc work; this can happen
* in two scenarios:
* 1. All threads are busy handling transactions
* In that case, one of those threads should call back into
* the kernel driver soon and pick up this work.
* 2. Threads are using the (e)poll interface, in which case
* they may be blocked on the waitqueue without having been
* added to waiting_threads. For this case, we just iterate
* over all threads not handling transaction work, and
* wake them all up. We wake all because we don't know whether
* a thread that called into (e)poll is handling non-binder
* work currently.
*/
binder_wakeup_poll_threads_ilocked(proc, sync);
}
include/linux/wait.h
wait.h
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
#define wake_up_interruptible_nr(x, nr) __wake_up(x, TASK_INTERRUPTIBLE, nr, NULL)
#define wake_up_interruptible_all(x) __wake_up(x, TASK_INTERRUPTIBLE, 0, NULL)
#define wake_up_interruptible_sync(x) __wake_up_sync((x), TASK_INTERRUPTIBLE, 1)
drivers/android/binder_alloc.h
binder_alloc.h
struct binder_alloc
/**
* struct binder_alloc - per-binder proc state for binder allocator
* @vma: vm_area_struct passed to mmap_handler
* (invarient after mmap)
* @tsk: tid for task that called init for this proc
* (invariant after init)
* @vma_vm_mm: copy of vma->vm_mm (invarient after mmap)
* @buffer: base of per-proc address space mapped via mmap
* @user_buffer_offset: offset between user and kernel VAs for buffer
* @buffers: list of all buffers for this proc
* @free_buffers: rb tree of buffers available for allocation
* sorted by size
* @allocated_buffers: rb tree of allocated buffers sorted by address
* @free_async_space: VA space available for async buffers. This is
* initialized at mmap time to 1/2 the full VA space
* @pages: array of binder_lru_page
* @buffer_size: size of address space specified via mmap
* @pid: pid for associated binder_proc (invariant after init)
* @pages_high: high watermark of offset in @pages
*
* Bookkeeping structure for per-proc address space management for binder
* buffers. It is normally initialized during binder_init() and binder_mmap()
* calls. The address space is used for both user-visible buffers and for
* struct binder_buffer objects used to track the user buffers
*/
//open系统调用时返回的fd信息的private_data里是binder_proc,而mmap过程会修改这个binder_proc的alloc字段信息,从而确保申请的内存位于target process对应的内核空间
struct binder_alloc {
}
include/linux/rbtree.h
rbtree.h//红黑树
rb_node
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));