架构思考和实现Inner
分层架构
https://developer.android.com/jetpack/guide#overview
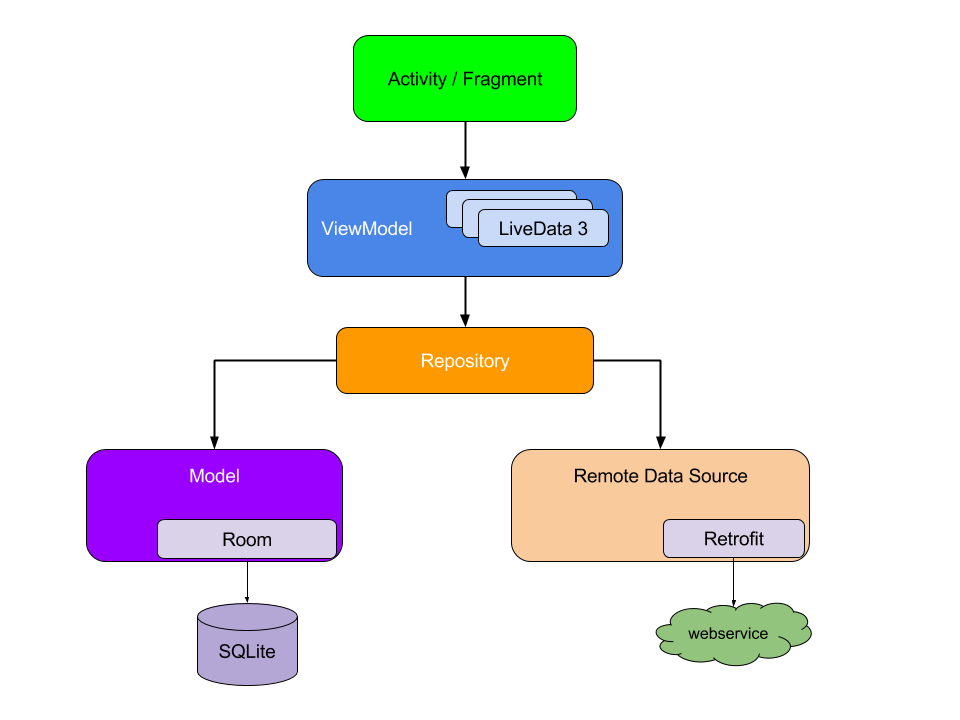
NetworkBoundResource数据策略
https://developer.android.com/jetpack/guide#addendum
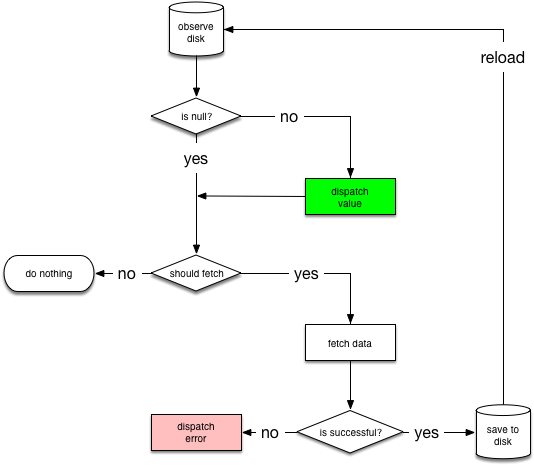
ResueViewmodels
Should I reuse view models in different views?
I noticed that I have views that need the same information like others. But sometimes you need 5 properties of the view model and sometimes only 2.
Do you share such view model over many views or do you create a separate view model for each view or maybe do you prefere an inheritance or composition strategy?
For me there are some disadvantages for sharing view models:
- Principle of Least Surprise: It is strange to fill only 2 properties of 5 of a view model and get null reference exception, because you don’t want to query additional data of the database. When the view model has 5 properties I expect that all are filled. The exceptions prove the rule. Unused properties make the code less readable (Why is that property present if it isn’t being used?)
- Separation of Concerns/Single Responsibility Principle: The view model cluttered up on complex sites, because you have to suit different needs for each view. If logic is involved its getting more complex, too.Also, sometimes you may want to add extra properties in your ViewModel that are absolutely specific to your View and that you don’t need in other Views.
- I think it puts the burden on the view to decide which ViewModel to call and that can get confusing.
What do you think? How do you handle such circumstances?
Answers:
In the project I am working on, each view has its own ViewModel, however we also have CollectionViewModels, which are shared/referenced by multiple view models.
Think - a list of Suppliers, that needs to be displayed in multiple screens in your application - and is bound to a variety of controls - a list box, grid view, whatever you need. Having just one ViewModel makes for simpler update/refresh logic of the list of Suppliers.
TLDR: I would only reuse view models, if all usage cases use the ViewModel in the same way. I.e. they all use the same properties etc.
graph LR
subgraph 合理
View1(View)-->|combine|PageViewModel1("PageViewModel1(VOLiveData,VOLiveData,...)")-->DomainRepositoryNew1("DomainRepository1(Flow)")
PageViewModel1-->DomainRepositoryNew2("DomainRepository2(Flow)")
PageViewModel1-->DomainRepositoryNew3("DomainRepository3(Flow)")
DomainRepositoryNew1-->LocalDataSourceNew1("LocalDataSource1")
DomainRepositoryNew1-->RemoteDataSourceNew1("RemoteDataSource1")
end
subgraph 不合理
View(View)-->|combine|DomainViewModel1("DomainViewModel1(DTOLiveData,DTOLiveData,...)")-->DomainRepository1("DomainRepository1(Flow)")
View(View)-->|combine|DomainViewModel2("DomainViewModel2(DTOLiveData,DTOLiveData,...)")-->DomainRepository2("DomainRepository2(Flow)")
View(View)-->|combine|DomainViewModel3("DomainViewModel3(DTOLiveData,DTOLiveData,...)")-->DomainRepository3("DomainRepository3(Flow)")
DomainRepository1-->LocalDataSource1("LocalDataSource1")
DomainRepository1-->RemoteDataSource1("RemoteDataSource1")
end
PageViewModel层内复用
graph LR
PageViewModel层内复用方式-->UseCase("类似UseCase(plaid项目)添加中间层对repository进行访问")
PageViewModel层内复用方式-->Viewmodel继承或组合,委托
PageViewModel层内复用方式-->interface多实现进行复用
Slicing your ViewModel with Delegates
Kotlin delegates in Android development — Part 2
OptimizeOfNetworkBoundResource
- 使用Coroutine Flow替代基于MediatorLiveData的回调通知
- 取消回调,可读性增加,协程的异步处理更加优雅,替代了原本appExecutors的线程切换和回调
- 支持使用flow的各种操作符
- 支持更细粒度的异步任务取消,原本仅支持异步任务之间的取消(通过MediatorLiveData实现取消监听),修改后支持协程挂起函数内部的两种不同的取消方式,参考博客中协程取消的文章
-
loadFromDb返回值进行Resource包裹,以支持失败等异常情况处理
-
loadFromDb太具体,改为loadFromLocal
-
异步任务封装为挂起函数,子类继承时按需选择是否需要切换线程以及选择线程类型,提升灵活性
另外saveCallResult不在约束为只能固定在io线程
-
Use combine instead of extend, because
- Sometimes we don’t want to implement all the abstract method.
- Generic type can be auto inferred
- Wrap this class is more convenient then subClass it,Wrap NetworkBoundResource if you don’t like the callback-like usage or reuse code
the disadvantage is that if we use function parameters passed to NetworkBoundResource constructor, each function will generate a lambda class and new instance when do construct NetworkBoundResource, which can be optimize by inline keyword.
-
https://medium.com/androiddevelopers/coroutines-on-android-part-ii-getting-started-3bff117176dd
//Wrap NetworkBoundResource if you don't like the callback-like usage or reuse code return NetworkBoundResource( localDataLoader = { withContext(Dispatchers.IO) { LogUtil.logWithThread(TAG, "loadFromLocal begin") val localResource = userLocalDataSource.login(userName) LogUtil.logWithThread(TAG, "loadFromLocal end") localResource } }, remoteDataLoader = { //use coroutineScope {} or supervisorScope {} to get CoroutineScope which will be used to propagate parentContext //to receive parent(viewModel) cancellation event coroutineScope { val result1 = async(Dispatchers.IO) { LogUtil.logWithThread(TAG, "loadFromRemote1, this = $this") userRemoteDataSource.login(userName, password) } val result2 = async(Dispatchers.IO) { LogUtil.logWithThread(TAG, "loadFromRemote2, this = $this") userRemoteDataSource.loginWithCallbackAdapter(userName, password) } val resource1 = result1.await() val resource2 = result2.await() Resource.success("${resource1.data} \n ${resource2.data}") } }, saveRemoteResult = { data -> LogUtil.logWithThread(TAG, "saveRemoteResult") userLocalDataSource.saveUid(userName, data) } ).loadAsFlow() -
/** * async issue: * --async callback: suspendCancellableCoroutine{} + resume * -- sync : call directly * * cancelable issue: * -- io thread: suspendCancellableCoroutine{} + cont.invokeOnCancellation * -- cpu thread: coroutineScope{} + isActive */ private suspend fun loginWithCallbackAdapterInner(userName: String, password: String) = withContext(Dispatchers.IO) {//switch thread if you want suspendCancellableCoroutine<Resource<String>> { cont -> LogUtil.logWithThread( UserRepository.TAG, "loginWithCallbackAdapterInner cont = $cont" ) //set cancellation handler before start sync request //use CoroutineScope.isActive collaborative cancellation when doing cpu intensive work cont.invokeOnCancellation { LogUtil.logWithThread(UserRepository.TAG, "onCancellation2 cause = $it") } //sync or async callback, cancellation handler will be invoked before cont.resume, //after continuation cancel event happened CallbackContainer().start(object : CallbackContainer.Callback() { override fun onSuccess() { cont.resume( Resource.success("Uid from remote adapter userName = $userName + password = $password ."), onCancellation = { cause: Throwable -> }) } override fun onFailed(throwable: Throwable) { cont.resumeWithException(throwable) } }) } }
multiShots时使用Flow的callbackFlow
应用架构指南
Common architectural principles
Separation of concerns–单一职责
Drive UI from a model
Best practices
- Avoid designating your app’s entry points—such as activities, services, and broadcast receivers—as sources of data.
- Create well-defined boundaries of responsibility between various modules of your app.
- Expose as little as possible from each module.
- Consider how to make each module testable in isolation.
- Focus on the unique core of your app so it stands out from other apps.
- Persist as much relevant and fresh data as possible.
- Assign one data source to be the single source of truth.
Single source of truth
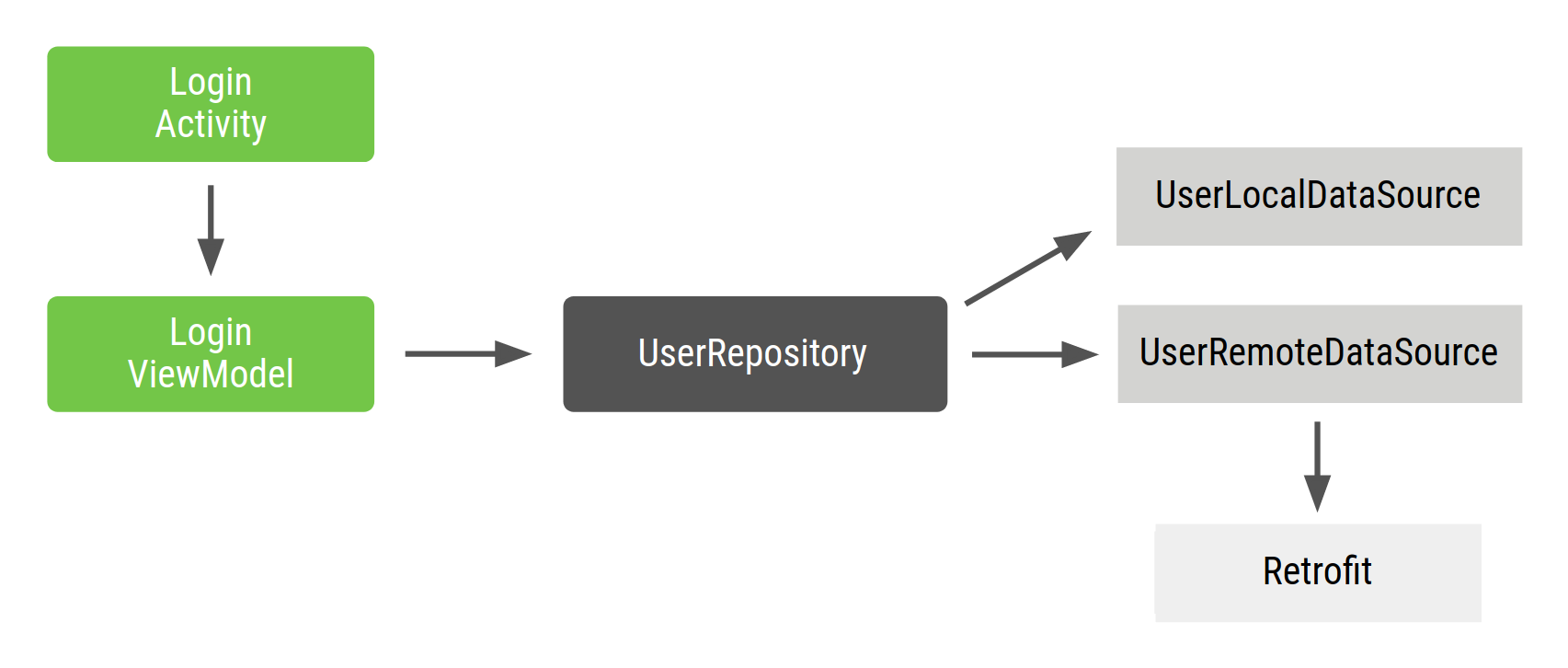
It’s common for different REST API endpoints to return the same data. For example, if our backend has another endpoint that returns a list of friends, the same user object could come from two different API endpoints, maybe even using different levels of granularity. If the UserRepository were to return the response from the Webservice request as-is, without checking for consistency, our UIs could show confusing information because the version and format of data from the repository would depend on the endpoint most recently called.
For this reason, our UserRepository implementation saves web service responses into the database. Changes to the database then trigger callbacks on active LiveData objects. Using this model, the database serves as the single source of truth, and other parts of the app access it using our UserRepository. Regardless of whether you use a disk cache, we recommend that your repository designate a data source as the single source of truth for the rest of your app.
DataBinding
DataBinding包中的ObservebleFile作用跟LiveData基本一致,但ObservebleFile有一个去重的效果,
为什么很多人说DataBinding很难调试?
经常听一些小伙伴提DataBinding不好用,原因是要在xml中写业务逻辑不好调试,对于这个观点我是持否定态度的。并不是我同意xml中写业务逻辑这一观点,我觉得碰到问题就得去解决问题,如果解决问题的路上有障碍就尽量扫清障碍,而不是一味的逃避。
如{vm.isShow ? View.VISIBLE : View.GONE}之类的业务逻辑不写在xml放在哪好呢?关于这个问题我在上篇文章Data Mapper章节中描述的很清楚,拿到后端数据转换成本地模型(此过程会编写所有数据相关逻辑),本地模型与设计图一一对应,不但可以将视图与后段隔离,而且可以解决xml中编写业务逻辑的问题。
MVVM
MVVM其实是前端领域一个专注于界面开发的架构模式,总共分为View、ViewModel、Repository三个模块 (需严格按照单一设计原则划分)
View(视图层):专门做视图渲染以及UI逻辑的处理Repository(远程):代表远程仓库,从Repository取需要的数据ViewModel:Repository取出的数据需暂存到ViewModel,同时将数据映射到视图层
分层固然重要,但MVVM最核心点是通过ViewModel做数据驱动UI以及双向绑定的操作用来解决数据/UI的一致性问题。
好的架构不应该局限到某一种模式(MVC/MVP/MVVM)上,需要根据自己项目的实际情况不断添砖加瓦。如果你们的后端比较善变我建议引入Data Mapper的概念~如果你经常和同事开发同一个界面,可以试图将每一条业务逻辑封装到use case中,这样大概率可以解决Git冲突的问题..等等等等,总之只要能实实在在 提高 开发效率以及项目稳定性的架构就是好架构.
参考
ReuseViewModel的思考
废弃方案:
- (单一职责)DomainViewmodel怎样通过继承和组合实现自定义liveData数据效果,(最小知道原则)然后解决view对viewmodel
graph LR
View-->|VO!=DTO|PageViewModel("PageViewModel(VOLiveData,VOLiveData,...)")-->|combineOrInheritedMulti|DomainViewModel
View-->|VO==DTO|DomainViewModel("DomainViewModel(DTOLiveData,DTOLiveData,...)")-->Repository("Repository(Flow)")-->DataSource("DataSource(Flow)")
思考
- 多层之间的接口怎么约定
- 是否需要自动生成代码,需要的话,目标是怎样的效果