1Space
类设计
ART虚拟机提供了多种内存分配手段,它们分别由LargeObjectSpace、BumpPointerSpace、ZygoteSpace、RegionSpace、DlMallocSpace和RosAllocSpace六个类(叶子节点)来实现。ImageSpace用于.art文件的加载
classDiagram
class Space {
+GetNames()
+Contains()
+IsImageSpace()
+IsMallocSpace()
+isZygoteSpace()
+isBumpPointerSpace()
+IsRegionSpace()
}
class AllocSpace {
+GetByteAllocated()
+GetObjectsAllocated()
+Alloc()
+AllocThreadSafe()
+Free()
+FreeList()
}
Space <|-- ContinuousSpace
ContinuousSpace <|-- MemMapSpace
MemMapSpace <|-- ImageSpace
MemMapSpace <|-- ContinuousMemMapAllocSpace
AllocSpace <|-- ContinuousMemMapAllocSpace
AllocSpace <|-- LargeObjectSpace
Space <|-- DiscontinuousSpace
DiscontinuousSpace <|-- LargeObjectSpace
ContinuousMemMapAllocSpace <|-- BumpPointerSpace
ContinuousMemMapAllocSpace <|-- RegionSpace
ContinuousMemMapAllocSpace <|-- ZygoteSpace
ContinuousMemMapAllocSpace <|-- MallocSpace
MallocSpace <|-- DlMallocSpace
MallocSpace <|-- RosAllocSpace
LargeObjectSpace <|-- LargeObjectMapSpace
LargeObjectSpace <|-- FreeListSpace
SpaceBitmap


space_bitmap(-inl).h
static constexpr int kBitsPerIntPtrT = sizeof(intptr_t) * kBitsPerByte;
// System page size. We check this against sysconf(_SC_PAGE_SIZE) at runtime, but use a simple
// compile-time constant so the compiler can generate better code.
static constexpr int kPageSize = 4096;
// Required object alignment
static constexpr size_t kObjectAlignment = 8;
static constexpr size_t kLargeObjectAlignment = kPageSize;
typedef SpaceBitmap<kObjectAlignment> ContinuousSpaceBitmap;
typedef SpaceBitmap<kLargeObjectAlignment> LargeObjectBitmap;
template<size_t kAlignment>
class SpaceBitmap {
// Backing storage for bitmap.
std::unique_ptr<MemMap> mem_map_;
// This bitmap itself, word sized for efficiency in scanning.
uintptr_t* const bitmap_begin_;
Set(const mirror::Object* obj)
bool Set(const mirror::Object* obj) ALWAYS_INLINE {
return Modify<true>(obj);//obj是一个内存地址。Modify本身是又是一个模板函数
}
Modify(const mirror::Object* obj)
inline bool SpaceBitmap<kAlignment>::Modify(const mirror::Object* obj) {
uintptr_t addr = reinterpret_cast<uintptr_t>(obj);
//offset是obj和heap_begin_(内存基地址)的偏移量
const uintptr_t offset = addr - heap_begin_;
//先计算这个偏移量落在哪个字节中
const size_t index = OffsetToIndex(offset);
//再计算这个偏移量落在字节的哪个比特位上
const uintptr_t mask = OffsetToMask(offset);
//用index取出位图对应的字节(注意,位图存储空间是以字节为单位的,而不是以比特位为单位)
uintptr_t* address = &bitmap_begin_[index];//main
uintptr_t old_word = *address;
if (kSetBit) {//kSetBit为true的话,表示往位图中存储某个地址
if ((old_word & mask) == 0) {//如果该比特位还未设置,才设置
*address = old_word | mask;//设置mask比特位
}
} else {
//取消mask比特位,这相当于从位图中去除对应位置所保存的地址
*address = old_word & ~mask;
}
return (old_word & mask) != 0;
}
// <offset> is the difference from .base to a pointer address.
// <index> is the index of .bits that contains the bit representing
// <offset>.
static constexpr size_t OffsetToIndex(size_t offset) {
return (offset / kAlignment) / kBitsPerIntPtrT;//先对齐
}
template<typename T>
static constexpr T IndexToOffset(T index) {
return static_cast<T>(index * kAlignment * kBitsPerIntPtrT);
}
// Bits are packed in the obvious way.
static constexpr uintptr_t OffsetToMask(uintptr_t offset) {
return (static_cast<size_t>(1)) << ((offset / kAlignment) % kBitsPerIntPtrT);
}
Walk(ObjectCallback* callback, void* arg)
template<size_t kAlignment>
void SpaceBitmap<kAlignment>::Walk(ObjectCallback* callback, void* arg) {
//注意这个函数的参数,callback是回调函数,每次从位图中确定一个对象的地址后将回调它,main
uintptr_t end = OffsetToIndex(HeapLimit() - heap_begin_ - 1);
uintptr_t* bitmap_begin = bitmap_begin_;
for (uintptr_t i = 0; i <= end; ++i) {
uintptr_t w = bitmap_begin[i];
if (w != 0) {
uintptr_t ptr_base = IndexToOffset(i) + heap_begin_;
do {
const size_t shift = CTZ(w);//w中末尾为0的个数,也就是第一个值为1的索引位
//计算该索引位所存储的对象地址值,注意下面代码行中计算对象地址的公式
mirror::Object* obj = reinterpret_cast<mirror::Object*>(ptr_base + shift * kAlignment);
(*callback)(obj, arg);//回调callback,arg是传入的参数
w ^= (static_cast<uintptr_t>(1)) << shift;//清除该索引位的1,继续循环
} while (w != 0);
}
}
}
space.h
Space
class Space {
protected:
std::string name_; //表示一个Space对象的名称
/*GcRetentionPolicy是一个枚举变量,其定义如下:
enum GcRetentionPolicy {
//下面这个枚举值表示本空间无需GC
kGcRetentionPolicyNeverCollect,
//每次GC都需要回收本空间的垃圾对象
kGcRetentionPolicyAlwaysCollect,
//只在full GC的时候回收本空间的垃圾对象
kGcRetentionPolicyFullCollect,
}
*/
GcRetentionPolicy gc_retention_policy_;
......
};
ContinuousSpace
Continuous spaces have bitmaps, and an address range. Although not required, objects within continuous spaces can be marked in the card table.
// Address at which the space begins.
//ContinuousSpace代表一块内存地址连续的空间,begin_为该内存空间的起始地址
uint8_t* Begin() const {
return begin_;
}
// Current address at which the space ends, which may vary as the space is filled.
//可以将end_看作水位线。如果一个ContinuousSpace对象可分配内存的话,那么end_表示
//当前内存分配到哪了。end_最大不能超过下面的limit_成员变量
uint8_t* End() const {
return end_.LoadRelaxed();
}
// The end of the address range covered by the space.
//limit_是这块内存空间的末尾地址。end_不能超过limit_
uint8_t* Limit() const {
return limit_;
}
public:
//Capacity函数返回该空间的容量,值为limit_- begin_
virtual size_t Capacity() const {
return Limit() - Begin();
}
//Size函数返回该空间当前使用了多少,值为end_- begin_。
size_t Size() const {
return End() - Begin();
}
}
MemMapSpace
class MemMapSpace : public ContinuousSpace {
protected:
std::unique_ptr<MemMap>mem_map_;//该成员变量指向所管理的MemMap对象
}
ContinuousMemMapAllocSpace
Used by the heap compaction interface to enable copying from one type of alloc space to another.
class ContinuousMemMapAllocSpace : public MemMapSpace, public AllocSpace {
protected:
/*ContinuousSpaceBitmap为数据类型别名,其定义如下:
typedef SpaceBitmap<kObjectAlignment> ContinuousSpaceBitmap;
kObjectAlignment取值为8。下文将解释这三个成员变量的取值情况。*/
std::unique_ptr<accounting::ContinuousSpaceBitmap>live_bitmap_;
std::unique_ptr<accounting::ContinuousSpaceBitmap>mark_bitmap_;
std::unique_ptr<accounting::ContinuousSpaceBitmap>temp_bitmap_;
}
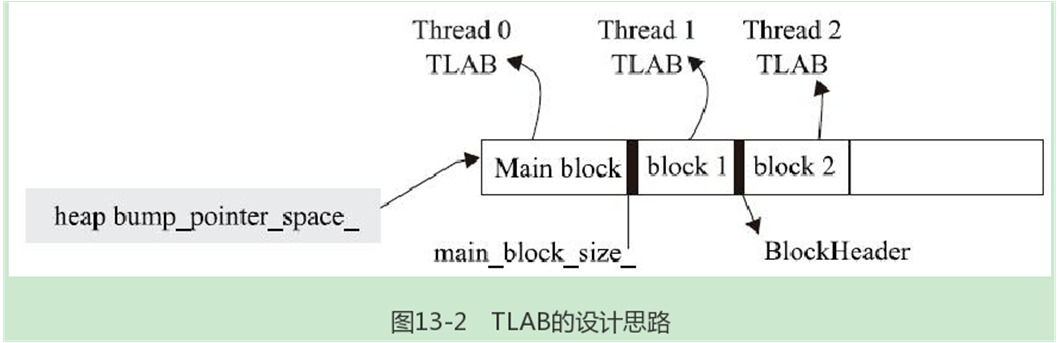
BumpPointerSpace
-
Sequential Allocation或Linear Allocation, 正因为BumpPointerSpace采用了如此简单的内存分配算法,所以它压根就不能释放某一次所分配的内存(和ZygoteSpace一样,Free等函数没有真正的实现),而只支持一次性释放所有已分配的内存(实现了AllocSpace的Clear函数)。
-
BumpPointer-Space非常适合做线程本地内存分配——Thread Local Allocation Blocks,简写为TLAB,它代表一块专属某个线程的内存资源
Create
// A bump pointer space allocates by incrementing a pointer, it doesn't provide a free
// implementation as its intended to be evacuated.
BumpPointerSpace* BumpPointerSpace::Create(const std::string& name,
size_t capacity, uint8_t* requested_begin) {
capacity = RoundUp(capacity, kPageSize);
std::string error_msg;
//创建MemMap对象
std::unique_ptr<MemMap> mem_map(MemMap::MapAnonymous(name.c_str(),
requested_begin, capacity,...));
.....
return new BumpPointerSpace(name, mem_map.release());
}
BumpPointerSpace::BumpPointerSpace(const std::string& name, MemMap* mem_map)
: ContinuousMemMapAllocSpace(name, mem_map, mem_map->Begin(),
mem_map->Begin(), mem_map->End(),GcRetentionPolicyAlwaysCollect),
growth_end_(mem_map->End()),//内存资源的尾部。分配的内存不允许超过该位置
objects_allocated_(0),//创建了多少个mirror Object对象
bytes_allocated_(0), //分配了多少字节的内存
block_lock_("Block lock", kBumpPointerSpaceBlockLock),
main_block_size_(0),//main_block_size_和num_blocks_的作用见下文代码分析
num_blocks_(0) {
}
Alloc
Alloc用于为某个mirror Object对象分配所需的内存。
inline mirror::Object* BumpPointerSpace::Alloc(Thread*, size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
/* Alloc函数的原型由AllocSpace类定义,其参数的含义为:
self:第一个参数。代表调用线程的线程对象,由于BumpPointerSpace没有使用这个参数,
所以上面的参数列表中并没有它(注意,第一个参数有参数类型,但没有参数名)。
num_bytes:第二个参数。此次内存分配所需的内存大小
bytes_allocated:实际分配了多少内存。它是一个输出参数。如果内存分配成功的话,该参数
大于或等于num_bytes。有一些内存分配算法会在实际所需内存大小上额外多分配一些内存用以
存储该算法所需的特殊信息。
usable_size:输出参数。如上文所说,实际分配的内存可能比所需内存要多。该变量表示所分配
的内存资源中可被外界使用的大小。显然,如果内存分配成功的话,该变量大于或等于num_bytes。
bytes_tl_bulk_allocated:它和thread local内存分配有关,其作用见下文代码分析。
另外,Alloc函数返回值的类型为mirror Object*。所以,Alloc就是用于为一个
Java Object对象(虚拟机中对应一个mirror Object对象)分配所需内存的函数。 */
//num_bytes按8字节向上对齐(kAlignment为8)
num_bytes = RoundUp(num_bytes, kAlignment);
mirror::Object* ret = AllocNonvirtual(num_bytes);//main
//设置返回值参数
if (LIKELY(ret != nullptr)) {
//BumpPointerSpace内存分配算法无需额外信息。所以实际分配内存大小就是num_bytes
//当然,num_bytes已经按8字节向上对齐
*bytes_allocated = num_bytes;
if (usable_size != nullptr) {
*usable_size = num_bytes;
}
*bytes_tl_bulk_allocated = num_bytes;
}
return ret;
}
AllocNonvirtual
inline mirror::Object* BumpPointerSpace::AllocNonvirtual(size_t num_bytes) {
//具体的内存分配由下面这个函数完成
mirror::Object* ret = AllocNonvirtualWithoutAccounting(num_bytes);
if (ret != nullptr) {
/*objects_allocated_和bytes_allocated_的类型为AtomicInteger,可在多个线程中实现原子操作。其中;
objects_allocated_:表示当前所分配的Object对象的个数。
bytes_allocated_:当前所分配的总内存大小。
下面的FetchAndAddSequentiallyConsistent函数为原子操作,相当于做加法。 */
objects_allocated_.FetchAndAddSequentiallyConsistent(1);
bytes_allocated_.FetchAndAddSequentiallyConsistent(num_bytes);
}
return ret;
}
AllocNonvirtualWithoutAccounting
inline mirror::Object* BumpPointerSpace::AllocNonvirtualWithoutAccounting(
size_t num_bytes) {
uint8_t* old_end;
uint8_t* new_end;
/*end_类型为Atomic<uint8_t*>,它是ContinuousSpace类的成员变量,它表示上一次内
存分配的末尾位置。也就是Bump Pointer的位置。BumpPointerSpace构造函数中,该成员变
量取值等于内存的起始位置。由于BumpPointerSpace的分配算法很简单,所以只需使用原子变量
即可实现多线程并发操作。 */
do {
old_end = end_.LoadRelaxed();//获取当前末尾位置
new_end = old_end + num_bytes;//计算新的末尾位置
if (UNLIKELY(new_end >growth_end_)) {//如果超过内存资源的大小,则返回空指针
return nullptr;
}
} while (!end_.CompareExchangeWeakSequentiallyConsistent(
old_end, new_end));
//while循环退出后,end_将指向最新的末尾位置new_end。此次内存分配得到的内存起始地址为old_end,main
return reinterpret_cast<mirror::Object*>(old_end);
}
AllocNewTlab
//AllocNewTlab:当ART虚拟机决定从调用线程的本地存储空间中分配内存时将调用此函数。
bool BumpPointerSpace::AllocNewTlab(Thread* self, size_t bytes) {
//注意参数,self代表调用线程,bytes代表此次内存分配的大小
MutexLock mu(Thread::Current(), block_lock_);
//先释放self线程原来的TLAB(Thread Local Allocation Buffer),TLAB其实就代表一块内存
RevokeThreadLocalBuffersLocked(self);
uint8_t* start = AllocBlock(bytes);//main
if (start == nullptr) {
return false;
}
//设置self线程的TLAB,起始位置为start,结束位置为start+bytes。TLAB的详情见下文介绍。
self->SetTlab(start, start + bytes);
return true;
}
AllocBlock
// Returns the start of the storage.
uint8_t* BumpPointerSpace::AllocBlock(size_t bytes) {
bytes = RoundUp(bytes, kAlignment);
/*num_blocks_表示当前分配了多少内存块。每次调用AllocBlock都对应一个内存块。
BumpPointerSpace中,这样的内存块由BlockHeader数据结构来描述,其内容为:
struct BlockHeader {
size_t size_; //内存块总大小
size_t unused_; //还剩多少空余内存
}; */
//如果是第一次分配内存块,则需要设置main_block_size_的值。UpdateMainBlock
//的实现很简单,就是将当前已经分配的内存大小(由end_减去begin_)赋值给main_block_size_
if (!num_blocks_) {
UpdateMainBlock();//内部的代码为:main_block_size_ = Size();
}
//分配内存,在原来所需内存大小的基础上加上BlockHeader结构体所需内存
uint8_t* storage = reinterpret_cast<uint8_t*>(
AllocNonvirtualWithoutAccounting(bytes + sizeof(BlockHeader)));//main
if (LIKELY(storage != nullptr)) {
BlockHeader* header = reinterpret_cast<BlockHeader*>(storage);
header->size_ = bytes;//设置BlockHeader的信息。
storage += sizeof(BlockHeader);//返回给外部使用者的内存不包括BlockHeader部分
++num_blocks_;//num_blocks_递增1
}
return storage;
}
Free(Thread*, mirror::Object*)
size_t Free(Thread*, mirror::Object*) OVERRIDE {
return 0;//直接返回0,说明BumpPointerSpace不能释放某一个Object所占据的内存
}
Clear
void BumpPointerSpace::Clear() {
if (!kMadviseZeroes) {//Linux平台上该值为true。
memset(Begin(), 0, Limit() - Begin());//将对应内存资源的内容清零
}
//下面这个函数的作用和上面代码中调用memset清零内存空间的效果类似,我们在11.4.7节中介绍过它
madvise(Begin(), Limit() - Begin(), MADV_DONTNEED), -1);
SetEnd(Begin());//设置end_等于begin_。
//所有相关成员变量恢复为初值
objects_allocated_.StoreRelaxed(0);
bytes_allocated_.StoreRelaxed(0);
growth_end_ = Limit();
{
MutexLock mu(Thread::Current(), block_lock_);
num_blocks_ = 0;
main_block_size_ = 0;
}
Walk(ObjectCallback* callback, void* arg)
void BumpPointerSpace::Walk(ObjectCallback* callback, void* arg) {
uint8_t* pos = Begin();
uint8_t* end = End();
uint8_t* main_end = pos;
{
{
MutexLock mu(Thread::Current(), block_lock_);
if (num_blocks_ == 0) {
UpdateMainBlock();//计算main block的大小。
}
main_end = Begin() + main_block_size_;
if (num_blocks_ == 0) {
end = main_end;
}
}
//先遍历main block
while (pos < main_end) {
mirror::Object* obj = reinterpret_cast<mirror::Object*>(pos);
/*判断这个obj是不是真实存在。从内存角度来说obj本身是存在的,因为上面代码中obj直
接由内存地址转换而来。所以obj肯定不为空指针。但obj可能并不是真正的对象。下面的
GetClass函数将获取该obj对应的klass_(该对象所属的类)。如果为空,说明obj并
不存在。对BumpPointerSpace使用的内存分配算法而言,也就没必要继续遍历了。
所以下面的if条件满足后,函数就直接返回了。*/
if (obj->GetClass<kDefaultVerifyFlags, kWithoutReadBarrier>() == nullptr) { return;}
else {
callback(obj, arg);//调用callback,main
//获取下一个对象的位置,
pos = reinterpret_cast<uint8_t*>(GetNextObject(obj));//main
}
}
//如果还有其他线程的TLAB的话,则继续遍历。此时就需要考虑BlockHeader的存在了
while (pos < end) {
BlockHeader* header = reinterpret_cast<BlockHeader*>(pos);
size_t block_size = header->size_;
pos += sizeof(BlockHeader);
mirror::Object* obj = reinterpret_cast<mirror::Object*>(pos);
const mirror::Object* end_obj = reinterpret_cast<const mirror::Object*>(pos + block_size);
while (obj < end_obj && obj->GetClass<kDefaultVerifyFlags,
kWithoutReadBarrier>() != nullptr) {
callback(obj, arg);
obj = GetNextObject(obj);
}
pos += block_size;
}
}
GetNextObject(mirror::Object* obj)
mirror::Object* BumpPointerSpace::GetNextObject(mirror::Object* obj) {
//obj表示当前所遍历的object对象的地址。那么,下一个对象的地址就是obj+obj的大小。
const uintptr_t position = reinterpret_cast<uintptr_t>(obj) + obj->SizeOf();
//按8字节对齐
return reinterpret_cast<mirror::Object*>(RoundUp(position, kAlignment));
}
GetBytesAllocated
uint64_t BumpPointerSpace::GetBytesAllocated() {
//由图13-2可知,bytes_allocated_表示main block部分所分配的内存大小
uint64_t total = static_cast<uint64_t>(bytes_allocated_.LoadRelaxed());
Thread* self = Thread::Current();
......
/*如果有多个线程使用TLAB,则需要计算它们的TLAB大小。 */
std::list<Thread*>thread_list = Runtime::Current()->GetThreadList()->GetList();
......
if (num_blocks_ > 0) {
for (Thread* thread : thread_list) {
total += thread->GetThreadLocalBytesAllocated();//Thread GetThreadLocalBytesAllocated返回值就是tlsPtr_.thread_local_end减去 tlsPtr_.thread_local_start的差。
}
}
return total;
}
RegionSpace
- RegionSpace的内存分配算法比BumpPointerSpace稍微高级一点。它先将内存资源划分成一个个固定大小(由kRegionSize指定,默认为1MB)的内存块。每一个内存块由一个Region对象表示。进行内存分配时,先找到满足要求的Region,然后从这个Region中分配资源。
class RegionSpace FINAL : public ContinuousMemMapAllocSpace {
......
//枚举变量RegionType用于描述内存块的类型。有些内容需要结合内存回收的相关知识才能理解,
//此处暂且不表
enum class RegionType : uint8_t {
kRegionTypeAll, kRegionTypeFromSpace,
kRegionTypeUnevacFromSpace, kRegionTypeToSpace,
kRegionTypeNone,
};
//枚举变量RegionState用于描述内存块的内存分配状态。
enum class RegionState : uint8_t {
kRegionStateFree, //内存块还未分配过内存
kRegionStateAllocated, //内存块分配过一些内存
/*如果需要分配比如3.5MB空间的话,则需要动用四个内存块。第一个内存块的状态将设置为
kRegionStateLarge,表示该Region为一个超过kRegionSize大小的内存的起始部分。
后面三个内存块的状态均为kRegionStateLargeTail。注意,第四个内存块将只用到0.5MB
的空间,剩下的0.5MB空间不能再用于内存分配。 */
kRegionStateLarge,
kRegionStateLargeTail,
};
}
Create
RegionSpace* RegionSpace::Create(const std::string& name, size_t capacity,
uint8_t* requested_begin) {
capacity = RoundUp(capacity, kRegionSize);//按1MB大小向上对齐
std::string error_msg;
//创建一个MemMap对象
std::unique_ptr<MemMap> mem_map(MemMap::MapAnonymous(name.c_str(),
requested_begin, capacity, ...));
......
//创建RegionSpace对象
return new RegionSpace(name, mem_map.release());
}
RegionSpace::RegionSpace(const std::string& name, MemMap* mem_map)
: ContinuousMemMapAllocSpace(name, mem_map, mem_map->Begin(),
mem_map->End(), mem_map->End(),kGcRetentionPolicyAlwaysCollect),
region_lock_("Region lock", kRegionSpaceRegionLock), time_(1U) {
size_t mem_map_size = mem_map->Size();
//计算有多少个Region,main
num_regions_ = mem_map_size / kRegionSize;//1MB
num_non_free_regions_ = 0U;//该成员变量表示已经占有的内存块个数
//创建Region数组
regions_.reset(new Region[num_regions_]);
uint8_t* region_addr = mem_map->Begin();
//初始化regions_数组的成员
for (size_t i = 0; i < num_regions_; ++i, region_addr += kRegionSize) {
//构造Region对象。region_addr表示该区域的起始地址,region_addr+kRegionSize
//为该内存区域的尾部地址
regions_[i] = Region(i, region_addr, region_addr + kRegionSize);
}
//full_region_表示一个内存资源不足的内存块,其用法见下文代码分析
full_region_ = Region();
//current_region_指向当前正在用的内存块,main
current_region_ = &full_region_;
//evac_region_成员变量的含义需要配合内存回收相关知识才能理解,我们后文碰到时再介绍
evac_region_ = nullptr;
}
Alloc
inline mirror::Object* RegionSpace::Alloc(Thread*, size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
//按8字节向上对齐
num_bytes = RoundUp(num_bytes, kAlignment);
return AllocNonvirtual<false>(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
}
template<bool kForEvac>
inline mirror::Object* RegionSpace::AllocNonvirtual(size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
//AllocNonvirtual函数有一个模板参数kForEvac。该参数和内存回收有关。我们先不讨论它。
//Alloc调用AllocNonvirtual时,kForEvac取值为false
mirror::Object* obj;
//如果所需内存小于kRegionSize,则从当前的region对象中分配
if (LIKELY(num_bytes <= kRegionSize)) {
if (!kForEvac) {
//调用Region的Alloc函数。由RegionSpace的Create函数可知,current_region_
//最初是指向full_region_的。所以,下面的Alloc肯定返回nullptr
obj = current_region_->Alloc(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);//main
} else {//如果kForEvac为true,则从evac_region_指向的Region中分配
obj = evac_region_->Alloc(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
}
//如果obj创建成功,则返回它
if (LIKELY(obj != nullptr)) { return obj; }
//如果执行到这,表明上面的内存分配失败。注意,上面的代码中并未使用锁同步。现在,
//我们需要重新尝试分配(因为有可能别的线程设置了current_region_,使得它指向
//一个新的内存块,而这个内存块里说不定就有空闲的内存资源)
MutexLock mu(Thread::Current(), region_lock_);
//具体的内存分配代码和上面完全一样
if (!kForEvac) {
obj = current_region_->Alloc(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);//main
} else {
obj = evac_region_->Alloc(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
}
if (LIKELY(obj != nullptr)) { return obj; }
//如果此时内存还分配失败(说明其他线程没有更新current_region_),则我们需要自己
//来遍历regions_数组以找到一个空闲的内存块,main
if (!kForEvac) {
/*RegionSpace的用法和Copying垃圾回收方法有关,该方法要求预留一半的内存作为
fromspace。所以,在下面的if条件中,如果已经被占用的内存块个数超过总内存块个数的
一半,则不再允许内存分配。*/
if ((num_non_free_regions_ + 1) * 2 >num_regions_) { return nullptr;}
//遍历内存块,找到一个空闲的内存块
for (size_t i = 0; i <num_regions_; ++i) {
Region* r = ®ions_[i];//main
//Region IsFree返回region state_成员变量的值。regions_数组中各个Region
//对象的state_初值为kRegionStateFree,表示内存块还未分配过内存
if (r->IsFree()) {
//Region Unfree设置state_的值为kRegionStateAllocated,同时设置
//type_为kRegionTypeToSpace
r->Unfree(time_);
r->SetNewlyAllocated();
++num_non_free_regions_;
obj = r->Alloc(num_bytes, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);//main
current_region_ = r;//更新current_region_
return obj;
}
}
} else {
//kForEvac为true的处理
......
}
AllocNewTlab
bool RegionSpace::AllocNewTlab(Thread* self) {
MutexLock mu(self, region_lock_);
RevokeThreadLocalBuffersLocked(self);
//同Alloc函数里的注释一样,我们要预留一半的空间
if ((num_non_free_regions_ + 1) * 2 > num_regions_) {
return false;
}
//找到一个空闲的Region对象
for (size_t i = 0; i < num_regions_; ++i) {
Region* r = ®ions_[i];
if (r->IsFree()) {
r->Unfree(time_);
++num_non_free_regions_;
r->SetTop(r->End());
//将这个Region和对应的线程关联起来,main
r->is_a_tlab_ = true;
r->thread_ = self;
//对线程而言,它只需要关注TLAB是否存在。如果存在的话,这块内存有多大。线程并不关心
//内存是由哪个Space以何种方式提供。
self->SetTlab(r->Begin(), r->End());
return true;
}
}
return false;
}
Free(Thread*, mirror::Object*)
size_t Free(Thread*, mirror::Object*) OVERRIDE {
UNIMPLEMENTED(FATAL);//不能释放单个对象所分配的内存
return 0;
}
Clear
void RegionSpace::Clear() {
MutexLock mu(Thread::Current(), region_lock_);
//遍历regions_数组
for (size_t i = 0; i < num_regions_; ++i) {
Region* r = ®ions_[i];
if (!r->IsFree()) {
--num_non_free_regions_;
}
r->Clear();//调用Region Clear
}
current_region_ = &full_region_;
evac_region_ = &full_region_;
}
Walk(ObjectCallback* callback, void* arg)
void Walk(ObjectCallback* callback, void* arg) {
WalkInternal<false>(callback, arg);
}
RegionSpace::Region
class Region {
public:
Region()
//idx_为内存块在RegionSpace regions_数组中的索引
: idx_(static_cast<size_t>(-1)),
//begin_和end_代表内存资源的起始位置,top_为内存分配的水位线
begin_(nullptr), top_(nullptr), end_(nullptr),
state_(RegionState::kRegionStateAllocated),
type_(RegionType::kRegionTypeToSpace),
//objects_allocated_表示创建了多少个Object对象,
objects_allocated_(0),
......
//is_a_tlab_表示该内存块是否被用作TLAB,thread_表示用它作TLAB的线程
is_a_tlab_(false), thread_(nullptr) {
//RegionSpace构造函数中,full_region_成员变量通过这个构造函数来创建
}
//RegionSpace构造函数中,regions_数组中的Region元素通过下面这个构造函数来创建
Region(size_t idx, uint8_t* begin, uint8_t* end)
: idx_(idx), begin_(begin), top_(begin), end_(end),
state_(RegionState::kRegionStateFree),
type_(RegionType::kRegionTypeNone),
...... {}
}
Alloc
inline mirror::Object* RegionSpace::Region::Alloc(size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
//atomic_top指向当前内存分配的位置
Atomic<uint8_t*>* atomic_top = reinterpret_cast<Atomic<uint8_t*>*>(&top_);
uint8_t* old_top;
uint8_t* new_top;
//更新分配后的内存位置
do {
old_top = atomic_top->LoadRelaxed();
new_top = old_top + num_bytes;
if (UNLIKELY(new_top > end_)) { return nullptr; }
} while (!atomic_top->CompareExchangeWeakSequentiallyConsistent(
old_top, new_top));
reinterpret_cast<Atomic<uint64_t>*>(&objects_allocated_)->
FetchAndAddSequentiallyConsistent(1);
*bytes_allocated = num_bytes;
if (usable_size != nullptr) {
*usable_size = num_bytes;
}
*bytes_tl_bulk_allocated = num_bytes;
return reinterpret_cast<mirror::Object*>(old_top);
}
Clear
void Clear() {
top_ = begin_;
state_ = RegionState::kRegionStateFree;
type_ = RegionType::kRegionTypeNone;
objects_allocated_ = 0;
alloc_time_ = 0;
live_bytes_ = static_cast<size_t>(-1);
if (!kMadviseZeroes) {memset(begin_, 0, end_ - begin_);}
madvise(begin_, end_ - begin_, MADV_DONTNEED);
is_newly_allocated_ = false;
is_a_tlab_ = false;
thread_ = nullptr;
}
MallocSpace
MallocSpace::MallocSpace(const std::string& name, MemMap* mem_map,
....., bool create_bitmaps,.....)
: ContinuousMemMapAllocSpace(name, mem_map,....
kGcRetentionPolicyAlwaysCollect),
...... {
//DlMallocSpace和RosAllocSpace创建时均设置create_bitmaps为true
if (create_bitmaps) {
//bitmap_index_是一个全局静态变量,用于给位图对象命名
size_t bitmap_index = bitmap_index_++;
......
/*创建live_bitmap_和mark_bitmap_。我们不关心它们的命名。这两个位图对象覆盖的内存
范围从MemMap Begin开始,大小是MemMap Size(NonGrowthLimitCapacity函数内部
调用MemMap Size)。简单点说,live_bitmap_和mark_bitmap_位图对象所包含的位图数
组恰好覆盖了这个MallocSpace所关联的MemMap内存空间。*/
live_bitmap_.reset(accounting::ContinuousSpaceBitmap::Create(...,Begin(),NonGrowthLimitCapacity()));
mark_bitmap_.reset(accounting::ContinuousSpaceBitmap::Create(..., Begin(), NonGrowthLimitCapacity()));
heap.cc
Heap::CreateMallocSpaceFromMemMap
space::MallocSpace* Heap::CreateMallocSpaceFromMemMap(MemMap* mem_map,
size_t initial_size, size_t growth_limit, size_t capacity,
const char* name, bool can_move_objects) {
/*注意参数,mem_map代表一块内存空间,内存的分配和释放均是在它上面发生的。
initial_size为内存空间初始分配大小。
growth_limit为最大的内存可分配位置,而capacity则为实际内存空间的容量。
growth_limit可以动态调整,但是不能超过capacity。
can_move_objects参数的含义和一种垃圾回收的算法有关。我们以后碰到相关代码时再
来介绍它。 */
space::MallocSpace* malloc_space = nullptr;
if (kUseRosAlloc) {//编译常量,默认为true,即ART优先使用rosalloc
//kDefaultStartingSize为编译常量,大小为4K。下面将创建RosAllocSpace对象
//low_memory_mode_表示是否为低内存模式。只有RosAllocSpace支持该模式
malloc_space = space::RosAllocSpace::CreateFromMemMap(
mem_map, name, kDefaultStartingSize, initial_size,
growth_limit,apacity,low_memory_mode_,can_move_objects);
} else {
//使用DlMallocSpace。它不支持low memory模式
malloc_space = space::DlMallocSpace::CreateFromMemMap(mem_map, name,
kDefaultStartingSize,initial_size, growth_limit,
capacity, can_move_objects);
}
//kUseRememberedSet值为true,下面这段if代码的相关知识留待13.8节介绍
if (collector::SemiSpace::kUseRememberedSet&&
non_moving_space_ != main_space_) {
//创建一个RememberedSet对象。详情见13.8节的内容
accounting::RememberedSet* rem_set =
new accounting::RememberedSet(std::string(name) +
" remembered set", this, malloc_space);
AddRememberedSet(rem_set);
}
malloc_space->SetFootprintLimit(malloc_space->Capacity());
return malloc_space;
}
dlmalloc_space.cc
DlMallocSpace
Create
DlMallocSpace* DlMallocSpace::Create(const std::string& name,
size_t initial_size, size_t growth_limit, size_t capacity,
uint8_t* requested_begin, bool can_move_objects) {
uint64_t start_time = 0;
size_t starting_size = kPageSize;
//先创建内存资源
MemMap* mem_map = CreateMemMap(name, starting_size, &initial_size,
&growth_limit, &capacity, requested_begin);
//再创建DlMallocSpace对象。CreateFromMemMap的代码见下文
DlMallocSpace* space = CreateFromMemMap(......);
return space;
}
CreateFromMemMap
DlMallocSpace* DlMallocSpace::CreateFromMemMap(MemMap* mem_map,
const std::string& name, size_t starting_size,
size_t initial_size, size_t growth_limit, size_t capacity,
bool can_move_objects) {
//内部调用dlmalloc的接口,starting_size为初始大小,initial_size为dlmalloc的
//limit水位线。CreateMspace返回的mspace为dlmalloc内部使用的结构,外界用void*
//作为它的数据类型,main
void* mspace = CreateMspace(mem_map->Begin(), starting_size, initial_size);
....
uint8_t* end = mem_map->Begin() + starting_size;
//调用mprotect保护从starting_size水位线到capacity这段内存,后续将根据需要进行调整
if (capacity - starting_size > 0) {
CHECK_MEMORY_CALL(mprotect, (end, capacity - starting_size, PROT_NONE),name);
}
uint8_t* begin = mem_map->Begin();
if (Runtime::Current()->IsRunningOnMemoryTool()) {
......
} else {//构造DlMallocSpace对象,它的参数比较多。将mspace传给DlMallocSPace,main
return new DlMallocSpace(mem_map, initial_size, name, mspace, begin,
end, begin + capacity,growth_limit, can_move_objects,
starting_size);
}
}
void* DlMallocSpace::CreateMspace(void* begin, size_t morecore_start,
size_t initial_size) {
errno = 0;
//create_mspace_with_base和mspace_set_footprint_limit均是dlmalloc的API
void* msp = create_mspace_with_base(begin, morecore_start, false);
if (msp != nullptr) {
mspace_set_footprint_limit(msp, initial_size);
}
......
return msp;
}
rosalloc_space.cc
RosAllocSpace
Create
RosAllocSpace* RosAllocSpace::Create(const std::string& name,
size_t initial_size, size_t growth_limit, size_t capacity,
uint8_t* requested_begin, bool low_memory_mode,
bool can_move_objects) {
uint64_t start_time = 0;
//kDefaultStartingSize取值为一个内存页的大小,对x86 32位平台而言,其值为4KB
size_t starting_size = Heap::kDefaultStartingSize;
//先创建一个MemMap对象
MemMap* mem_map = CreateMemMap(name, starting_size, &initial_size,
&growth_limit, &capacity, requested_begin);
//再创建RosAllocSpace对象
RosAllocSpace* space = CreateFromMemMap(......);
return space;
}
CreateFromMemMap
RosAllocSpace* RosAllocSpace::CreateFromMemMap(MemMap* mem_map,
const std::string& name, size_t starting_size,
size_t initial_size,size_t growth_limit, size_t capacity,
bool low_memory_mode, bool can_move_objects) {
bool running_on_memory_tool = Runtime::Current()->IsRunningOnMemoryTool();
//CreateRosAlloc将创建rosallc对象,main
allocator::RosAlloc* rosalloc = CreateRosAlloc(
mem_map->Begin(), starting_size, initial_size,
capacity, low_memory_mode, running_on_memory_tool);
uint8_t* end = mem_map->Begin() + starting_size;
uint8_t* begin = mem_map->Begin();
if (running_on_memory_tool) {
......
} else {//构造一个RosAllocSpace对象。RosAllocSpace构造函数和
//DlMallocSpace构造函数类似,都很简单,笔者不拟介绍它。
return new RosAllocSpace(mem_map, initial_size, name, rosalloc,...);
}
}
allocator::RosAlloc* RosAllocSpace::CreateRosAlloc(void* begin,
size_t morecore_start,size_t initial_size,
size_t maximum_size, bool low_memory_mode,....) {
errno = 0;
//new一个RosAlloc对象,它就是rosalloc模块。低内存模式将影响rosalloc内存释放的算法
allocator::RosAlloc* rosalloc = new art::gc::allocator::RosAlloc(
begin, morecore_start, maximum_size,
low_memory_mode ? art::gc::allocator::RosAlloc::kPageReleaseModeAll :
art::gc::allocator::RosAlloc::kPageReleaseModeSizeAndEnd,
running_on_memory_tool);
if (rosalloc != nullptr) {
rosalloc->SetFootprintLimit(initial_size);
} ......
return rosalloc;
}
RosAlloc::RosAlloc(void* base, size_t capacity, size_t max_capacity,
PageReleaseMode page_release_mode,
bool running_on_memory_tool, size_t page_release_size_threshold)
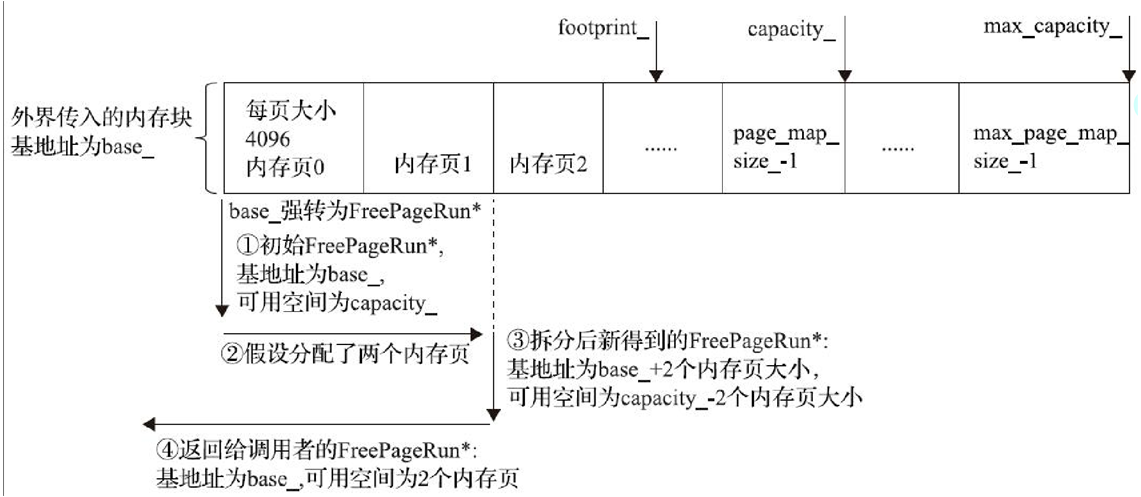
: base_(reinterpret_cast<uint8_t*>(base)), footprint_(capacity),
capacity_(capacity), max_capacity_(max_capacity),
...... {
....
/*图13-4、图13-5中的bracketSizes、headSizes和numOfPages等数组均为RosAlloc态
的静成员变量。下面的Initialize函数将初始化它们。初始化的结果已经绘制在图13-4、
图13-5中了。感兴趣的读者可自行研究该函数的代码。*/
if (!initialized_) { Initialize(); }
//创建同步锁,一共42个。当从不同粒度的内存资源池中分配内存时将使用不同的同步锁
//对象进行保护。这样处理的好处是可提高内存分配的并发效率
for (size_t i = 0; i <kNumOfSizeBrackets; i++) {
size_bracket_lock_names_[i] =
StringPrintf("an rosalloc size bracket %d lock", static_cast<int>(i));
size_bracket_locks_[i] = new Mutex(
size_bracket_lock_names_[i].c_str(), kRosAllocBracketLock);
/*current_runs_为Run*定长数组,元素个数为42。下面的代码将设置数组的内容都指向
dedicated_full_run_。dedicated_full_run_是RosAlloc的静态成员变量,类型为
Run*。它代表一块没有内存可供分配的资源池。一般而言,可以将current_runs_各个元素
设置为nullptr。但使用current_runs_的地方就需要判断其元素是否为nullptr。所以,
此处的做法是将current_runs_各成员指向这个无法分配资源的Run对象。这样就可以消除
空指针的判断。而代码处理dedicated_full_run_时就和处理其他那些正常的资源分配殆尽的
Run对象一样即可,后续我们将看到相关的代码。*/
current_runs_[i] = dedicated_full_run_;
}
size_t num_of_pages = footprint_ / kPageSize;
size_t max_num_of_pages = max_capacity_ / kPageSize;
std::string error_msg;
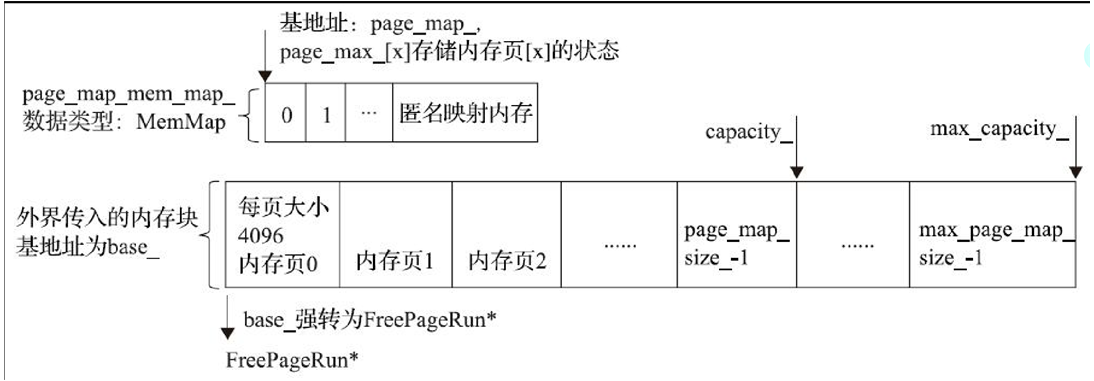
//创建page_map_mem_map_ MemMap对象,参考图13-6
page_map_mem_map_.reset(MemMap::MapAnonymous("rosalloc page map", nullptr,
RoundUp(max_num_of_pages, kPageSize),.....));
//page_map_mem_map_基地址是page_map_
page_map_ = page_map_mem_map_->Begin();
page_map_size_ = num_of_pages;//该RosAlloc所管理的内存页有多大,参考图13-6
max_page_map_size_ = max_num_of_pages;//内存最大有多少个内存页
//free_page_run_size_map_为vector数组,类型为size_t。其作用我们下文再介绍
free_page_run_size_map_.resize(num_of_pages);
//将base_强转成一个FreePageRun对象,可参考图13-6
FreePageRun* free_pages = reinterpret_cast<FreePageRun*>(base_);
//设置本free_pages对象的大小并释放相关内存页。最开始时base_所对应的内存块全部
//都是空闲的,所以第一个free_pages的大小为capacity_
free_pages->SetByteSize(this, capacity_);//main
free_pages->ReleasePages(this);//释放本free_pages所包含的内存,main
//free_page_runs_为set<FreePageRun*>容器
free_page_runs_.insert(free_pages);
}
RosAlloc::FreePageRun::SetByteSize
void SetByteSize(RosAlloc* rosalloc, size_t byte_size) {
/*下面两行代码的含义如下:
先得到本FreePageRun的基地址fpr_base。根据上面RosAlloc的构造函数可知,FreePageRun
对象是将base_内存块上的地址强制转换数据类型得到的。
ToPageMapIndex函数用于返回fpr_base在page_map_中的索引号。参考图13-6可知,page_map_
一个元素代表base_中一个内存页。所以,ToPageMapIndex的实现就很容易想到了,即用fpr_base-
base_,然后除以内存页大小即可算出该FreePageRun对象对应哪个内存页 */
uint8_t* fpr_base = reinterpret_cast<uint8_t*>(this);
size_t pm_idx = rosalloc->ToPageMapIndex(fpr_base);
//free_page_run_size_map_是一个数组,下面将设置对应索引的元素的值,
//用于表示对应FreePageRun对象所管理的内存空间大小
rosalloc->free_page_run_size_map_[pm_idx] = byte_size;
}
RosAlloc::FreePageRun::ReleasePages
void ReleasePages(RosAlloc* rosalloc) {
uint8_t* start = reinterpret_cast<uint8_t*>(this);
//ByteSize函数是上文SetByteSize函数的对应,用于返回free_page_run_size_map_
//对应元素的值。在RosAlloc构造函数调用流程中,byte_size返回为capacity_
size_t byte_size = ByteSize(rosalloc);
//ShouldReleasePages判断是否需要释放内存页。我们下文再介绍它
if (ShouldReleasePages(rosalloc)) {
//直接看下面这个函数。start表示本FreePageRun对象在base_内存块中的起始位置
rosalloc->ReleasePageRange(start, start + byte_size);//main
}
}
RosAlloc::ReleasePageRange
size_t RosAlloc::ReleasePageRange(uint8_t* start, uint8_t* end) {
//start和end参数用于指明要释放的内存的起始和终点位置
//清零这段内存
if (!kMadviseZeroes) { memset(start, 0, end - start);}
CHECK_EQ(madvise(start, end - start, MADV_DONTNEED), 0);
//调用者只是指明了内存段的起始和终点位置,我们需要将这个位置转换为RosAlloc内部的
//内存页位置
size_t pm_idx = ToPageMapIndex(start);//返回start位置对应的内存页索引号
size_t reclaimed_bytes = 0;
//返回end位置对应的内存页索引号
const size_t max_idx = pm_idx + (end - start) / kPageSize;
for (; pm_idx < max_idx; ++pm_idx) {
/*图13-6中曾说过,page_map_保存base_中各内存页的状态,kPageMapEmpty即为其中的
一种状态。内存页的初始状态为kPageMapReleased,表示内存在系统中还未分配。
kPageMapEmpty表示内存可以被回收。 */
if (page_map_[pm_idx] == kPageMapEmpty) {
reclaimed_bytes += kPageSize;//reclaimed_bytes表示此次回收的内存大小
page_map_[pm_idx] = kPageMapReleased;//设置对应内存页的状态
}
}
return reclaimed_bytes;
}
AllocCommon
inline mirror::Object* RosAllocSpace::AllocCommon(Thread* self,
size_t num_bytes, size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
size_t rosalloc_bytes_allocated = 0;
size_t rosalloc_usable_size = 0;
size_t rosalloc_bytes_tl_bulk_allocated = 0;
......
//调用RosAlloc的Alloc函数分配内存。我们下文会详细介绍rosalloc内存分配算法
mirror::Object* result = reinterpret_cast<mirror::Object*>(
rosalloc_->Alloc<kThreadSafe>(self, num_bytes,
&rosalloc_bytes_allocated, &rosalloc_usable_size,
&rosalloc_bytes_tl_bulk_allocated));
......
return result;
}
rosalloc.h
RosAlloc::Alloc
template<bool kThreadSafe>
inline ALWAYS_INLINE void* RosAlloc::Alloc(Thread* self,
size_t size, size_t* bytes_allocated,size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
//Alloc是一个模板函数,包含模板参数kThreadSafe,默认值为true。ART虚拟机中
//绝大部分情况下该模板参数都使用这个默认的true。我们重点介绍它的处理情况
//kLargeSizeThreshold为2KB。如果所需的内存超过2KB,则使用AllocLargeObject
//来处理。AllocLargeObject将留给读者自行阅读
if (UNLIKELY(size >kLargeSizeThreshold)) {
return AllocLargeObject(self, size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);
}
void* m;
//我们将着重介绍kThreadSafe为true的情况
if (kThreadSafe) {
m = AllocFromRun(self, size, bytes_allocated, usable_size,
bytes_tl_bulk_allocated);//main
} else {
.....//kThreadSafe为false的情况,读者在学完本节的基础上可自行研究它
}
return m;
}
RosAlloc::AllocFromRun
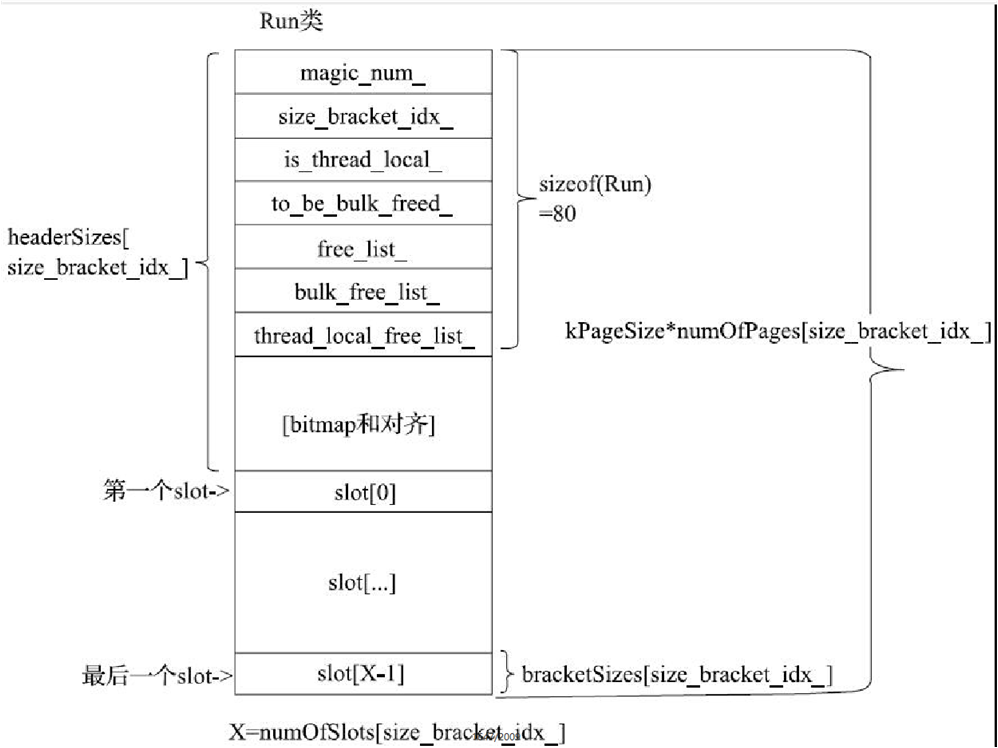
RosAlloc原理图
//RosAllocSpace
//kNumOfSizeBrackets值为42,描述每种slot所支持的内存分配粒度
static size_t bracketSizes[kNumOfSizeBrackets];
//numOfPages则记录了每种slot对应的内存资源有多少(以4KB字节为单位)
static size_t numOfPages[kNumOfSizeBrackets];

一个Run对应一种粒度(一行)
RosAllc::AllocFromRun流程图
graph TB
SizeToIndex("size_t idx = SizeToIndexAndBracketSize(size, &bracket_size)")-->indexBelow16{"idx < 16?"}
indexBelow16-->|yes|getRosAllocRun("Run* thread_local_run = self->GetRosAllocRun(idx)")
getRosAllocRun-->AllocSlot("slot_addr = thread_local_run->AllocSlot();")
AllocSlot-->slotAddrIsNull{"slot_addr == nullptr?"}
slotAddrIsNull-->|yes|RefillRun("thread_local_run = RefillRun(self, idx);")
RefillRun-->AllocSlot2("slot_addr = thread_local_run->AllocSlot();")
indexBelow16-->|no|AllocFromCurrentRunUnlocked("slot_addr = AllocFromCurrentRunUnlocked(self, idx);")
void* RosAlloc::AllocFromRun(Thread* self, size_t size,
size_t* bytes_allocated,size_t* usable_size, size_t*
bytes_tl_bulk_allocated) {
size_t bracket_size;
/*SizeToIndexAndBracketSize将根据调用者所期望分配的内存大小来决定使用哪种粒度的资源池
(idx表示索引号)以及这种资源池中slot的大小(由bracket_size决定)。*/
size_t idx = SizeToIndexAndBracketSize(size, &bracket_size);//main
void* slot_addr;
//kNumThreadLocalSizeBrackets取值为16。由图13-4可知,idx小于16的话,对应的内
//存分配粒度最大不超过128字节。所以,下面if条件满足的话,说明所要分配的内存大小小于
//128字节
if (LIKELY(idx<kNumThreadLocalSizeBrackets)) {
/*如果所需内存不超过128字节,我们会尝试从线程本地内存资源池中分配内存。注意,线程本地存储
内存池并不是前文提到的TLAB。但它和TLAB含义类似。只不过Thread类对rosalloc有单独的支持。下面的Thread GetRosAllocRun函数将返回tlsPtr_.rosalloc_runs数组对应索引的元
素。读者回顾7.5.2.1节可知,tlsPtr_有一个rosalloc_runs数组,包含16个元素,它们初始
化都指向RosAlloc的dedicated_full_run_对象。
这段if代码块表示当我们所需要的内存小于128字节时,RosAlloc将尝试从调用线程所拥有的本地
资源池中分配内存,这样就不需要同步锁的保护了,如此可提高内存分配的速度。
注意,由于初始值都指向dedicated_full_run_,下面的代码执行时将无须判断thread_local_
run是否为nullptr。*/
Run* thread_local_run = reinterpret_cast<Run*>(self->GetRosAllocRun(idx));
//tlsPtr_ rosallc_runs默认取值也是dedicated_full_run_,在这个Run对象中没有可分配内
//的内存资源。所以,首次调用下面的AllocSlot必然返回nullptr,表明当前这个Run中没有空闲存了
slot_addr = thread_local_run->AllocSlot();
if (UNLIKELY(slot_addr == nullptr)) {
/*如果slot_addr为空指针,说明thread_local_run这个Run中没有空余内存。
下面我们就需要解决这个问题。此时就需要同步锁的保护了。但我们只需要使用目标索引的同步
锁就行了。比如,分配8字节内存不够用时,我们就用保护8字节资源的同步锁。如此,它就不会
和保护其他内存资源的同步锁竞争,从而可提高内存分配速度。*/
MutexLock mu(self, *size_bracket_locks_[idx]);
bool is_all_free_after_merge;
/*参考图13-5,Run中有thread_local_free_list_和free_list_两个用于管理空闲slot
的SlotFreeList对象。MergeThreadLocalFreeListToFreeList函数将thread_local_
free_list_里的空闲资源合并到free_list_。
对于dedicate_full_run_来说,合并它们后,空闲资源并不会增加,所以该函数返回false。
请读者阅读掌握本章内容后再自行研究下面这个函数。*/
if (thread_local_run->MergeThreadLocalFreeListToFreeList(
&is_all_free_after_merge)) {......
} else {//MergeThreadLocalFreeListToFreeList返回false的情况
......
//RefillRun是重点,它将给idx所对应的Run对象添加内存资源,所以叫Refill
thread_local_run = RefillRun(self, idx);//main
.....
//将thread_local_run设置为调用线程的线程本地内存资源池
thread_local_run->SetIsThreadLocal(true);
self->SetRosAllocRun(idx, thread_local_run);
}
//bytes_tl_bulk_allocated表示本资源池中剩余的内存
*bytes_tl_bulk_allocated = thread_local_run->NumberOfFreeSlots() *
bracket_size;
//重新分配资源。AllocSlot非常简单,就是从free_list_中返回一个Slot对象。
slot_addr = thread_local_run->AllocSlot();//main
} else {//slot_addr不为nullptr的处理
*bytes_tl_bulk_allocated = 0;
}
*bytes_allocated = bracket_size;
*usable_size = bracket_size;
} else {
/*当所需内存超过128字节时,将从RosAlloc内部的资源池中分配。这个时候也需要
同步锁来保护了。当然,如上面代码一样,不同大小的资源池会使用不同的同步锁来保护。
AllocFromCurrentRunUnlocked将从RosAlloc的current_runs_[idx]中进行分配。
如果current_runs_[idx]对应的资源池内存资源不足,将会调用RefillRun给对应的资源池重新加满内存资源。*/
MutexLock mu(self, *size_bracket_locks_[idx]);
slot_addr = AllocFromCurrentRunUnlocked(self, idx);//main
if (LIKELY(slot_addr != nullptr)) {
*bytes_allocated = bracket_size;
*usable_size = bracket_size;
*bytes_tl_bulk_allocated = bracket_size;
}
}
return slot_addr;
}
RosAlloc::RefillRun
RosAlloc::Run* RosAlloc::RefillRun(Thread* self, size_t idx) {
......//这里还有一段处理,读者以后可自行研究这段代码
return AllocRun(self, idx);//我们看这个函数
}
RosAlloc::Run* RosAlloc::AllocRun(Thread* self, size_t idx) {
RosAlloc::Run* new_run = nullptr;
{
MutexLock mu(self, lock_);
/*AllocPages函数将从base_所在的内存中分配一段内存空间。这内存空间对外由一个Run
对象来管理。该空间的大小(以4KB为单位)由numOfPages[idx]决定。kPageMapRun
是内存页状态中的一种。 */
new_run = reinterpret_cast<Run*>(AllocPages(self,
numOfPages[idx], kPageMapRun));//main
}
if (LIKELY(new_run != nullptr)) {
new_run->size_bracket_idx_ = idx;
.....//清理这块内存资源池
//初始化Run对象中的free_list_成员。
new_run->InitFreeList();
}
return new_run;
}
RosAlloc::AllocPages
void* RosAlloc::AllocPages(Thread* self, size_t num_pages,
uint8_t page_map_type) {
//AllocPages是以内存页为单位进行分配的
lock_.AssertHeld(self);
FreePageRun* res = nullptr;//RosAlloc借助FreePageRun来管理内存分配
//req_bytes_size是以字节为单位的内存大小
const size_t req_byte_size = num_pages * kPageSize;
//free_pages_runs_为Set<FreePageRun*>,第一个元素在RosAlloc构造函数中添加,
//这个元素位于base_,所包含的空闲内存大小为capacity_。
for (auto it = free_page_runs_.begin(); it != free_page_runs_.end(); ) {
FreePageRun* fpr = *it;
size_t fpr_byte_size = fpr->ByteSize(this);
//如果当前的FreePageRun对象所管理的空闲内存资源比所需内存要多,则对当前fpr对象进行拆分
if (req_byte_size <= fpr_byte_size) {
free_page_runs_.erase(it++);//当前fpr对象从容器中移除
if (req_byte_size < fpr_byte_size) {
//新的fpr对象为当前fpr对象的起始位置+待分配内存大小
FreePageRun* remainder =
reinterpret_cast<FreePageRun*>(reinterpret_cast<uint8_t*>(fpr) + req_byte_size);
//新fpr对象所管理的空闲内存资源大小等于原fpr的大小减去此次分配的内存大小
remainder->SetByteSize(this, fpr_byte_size - req_byte_size);
free_page_runs_.insert(remainder);//把新的fpr对象加入容器
//更新原fpr对象所管理的内存资源大小,它将作为返回值返回给调用者
fpr->SetByteSize(this, req_byte_size);
}
res = fpr;
break;
} else { ++it; }
}
/*如果free_page_runs_中没有合适的FreePageRun对象,则考虑是否需要进行扩容。
base_所在的内存块初始设置的大小是capacity_,当前可用的大小由footprint_ base_所在的内存块初始设置的大小是capacity_,当前可用的大小由footprint_控制。如果footprint_小于capacity_,则还能继续扩容。这部分代码比较复杂,建议读者
学完本节后再自行阅读它*/
......
if (LIKELY(res != nullptr)) {
//更新内存页的状态信息。page_map_idx表示res这块新分配内存所对应的状态信息所在数组的索引
size_t page_map_idx = ToPageMapIndex(res);
switch (page_map_type) {
case kPageMapRun:
//如上文所述,page_map_保存了base_内存页的状态信息。如果一次分配了多个内存页的话,
//第一个内存页的状态将设置为kPageMapRun,其余内存页的状态为kPageMapRunPart
page_map_[page_map_idx] = kPageMapRun;
for (size_t i = 1; i < num_pages; i++) {
page_map_[page_map_idx + i] = kPageMapRunPart;
}
break;
......
}
return res;
}
InitFreeList
void InitFreeList() {
const uint8_t idx = size_bracket_idx_;
const size_t bracket_size = bracketSizes[idx];
const size_t bracket_size = bracketSizes[idx];
/*结合图13-5可知,FirstSlot函数这个Run中第一个slot的位置。代码中,一个slot由Slot类
表示。Slot内部有一个next_成员变量,指向下一个Slot对象。所以,一个Run中的Slot对象可
构成一个链表来管理。*/
Slot* first_slot = FirstSlot();
/*LastSlot返回Run中最后一个Slot的位置。free_list_是Run的成员变量,其数据类型
为SlotFreeList<false>,它是RosAlloc实现的一个用于管理Slot的容器。下面的for
循环将把图13-5 Run中的Slot对象通过free_list_管理起来。虽然下面的代码是从末尾
Slot向前遍历,但最终结果就是free_list_ head_指向第一个Slot对象。而Run中的所有
Slot对象又通过上面提到的Slot next_成员变量构成一个链表。 */
for (Slot* slot = LastSlot(); slot >= first_slot; slot =
slot->Left(bracket_size)) {
free_list_.Add(slot);
}
}
RosAlloc::Run::AllocSlot
inline void* RosAlloc::Run::AllocSlot() {
/*Remove将free_list_中移除head_所指向的那个Slot单元。从这一点可以看出,Run对Slot的管
理是比较简单的。就是通过一个链表把Slot单元管理起来,每次要分配的时候取链表的头部返回给
外界。*/
Slot* slot = free_list_.Remove();
.....
return slot;
}
// Compute numOfSlots and slotOffsets.
for (size_t i = 0; i < kNumOfSizeBrackets; i++) {
size_t bracket_size = bracketSizes[i];
size_t run_size = kPageSize * numOfPages[i];
size_t max_num_of_slots = run_size / bracket_size;
// Search for the maximum number of slots that allows enough space
// for the header.
for (int s = max_num_of_slots; s >= 0; s--) {
size_t tmp_slots_size = bracket_size * s;
if (tmp_slots_size + tmp_header_size <= run_size) {
// Found the right number of slots, that is, there was enough
// space for the header (including the bit maps.)
num_of_slots = s;
header_size = tmp_header_size;
break;
}
Free
size_t RosAllocSpace::Free(Thread* self, mirror::Object* ptr) {
....
return rosalloc_->Free(self, ptr);//调用RosAlloc的Free函数释放内存
}
DiscontinuousSpace
class DiscontinuousSpace : public Space {
protected:
/*LargeObjectBitmap为类型别名,其定义如下:
typedef SpaceBitmap<kLargeObjectAlignment>LargeObjectBitmap;
kLargeObjectAlignment为常量,值为内存页的大小(4KB)。SpaceBitmap的详情可回顾
7.6.1.1.1节的内容。简单来说,SpaceBitmap是一个位图数组,该数组以比特位为元素:
(1) 数组的每一位对应一段内存空间中一个内存单元的位置。内存单元的大小等于模板参数的值。
比如上面的kLargeObjectAlignment表示以一个内存单元大小为4KB
(2) 如果位图数组某个元素取值为1,则表明对应的内存单元中有内容。如果为0,则表示对应的内存单元没有内容。比如,我们在内存单元中创建了一个对象时,就需要修改位图数组中对应比特位元素的值为1。*/
std::unique_ptr<accounting::LargeObjectBitmap>live_bitmap_;
std::unique_ptr<accounting::LargeObjectBitmap>mark_bitmap_;
}
DiscontinuousSpace::DiscontinuousSpace(const std::string& name,
GcRetentionPolicy gc_retention_policy) :
Space(name, gc_retention_policy) {
const size_t capacity = static_cast<size_t>(std::numeric_limits<uint32_t>::max());
live_bitmap_.reset(accounting::LargeObjectBitmap::Create("large live objects", nullptr, capacity));
mark_bitmap_.reset(accounting::LargeObjectBitmap::Create("large marked objects", nullptr, capacity));
}
LargeObjectMapSpace
LargeObjectMapSpace* LargeObjectMapSpace::Create(const std::string& name) {
if (Runtime::Current()->IsRunningOnMemoryTool()) {......}
else {//构造一个LargeObjectMapSpace对象。其构造函数非常简单
return new LargeObjectMapSpace(name);
}
}
Alloc
mirror::Object* LargeObjectMapSpace::Alloc(Thread* self, size_t num_bytes,
size_t* bytes_allocated, size_t* usable_size,
size_t* bytes_tl_bulk_allocated) {
std::string error_msg;
//这就是LargeObjectMapSpace的内存分配算法,直接创建一个MemMap对象
MemMap* mem_map = MemMap::MapAnonymous("large object space allocation",
nullptr, num_bytes, PROT_READ | PROT_WRITE,
true, false, &error_msg);
//将这块内存映射空间的基地址转换为返回值的类型
mirror::Object* const obj = reinterpret_cast<mirror::Object*>(
mem_map->Begin());
MutexLock mu(self, lock_);
/*large_objects_是LargeObjectMapSpace的成员变量,类型为
AllocationTrackingSafeMap<mirror::Object*, LargeObject,
kAllocatorTagLOSMaps>。读者不要被这个看起来很复杂的数据结构吓到,
AllocationTrakingSafeMap其实就是一个map,key的类型是Object*,value的类型是
LargeObject。LargeObject是LargeObjectMapSpace中的内部类,用于保存该内存映射
空间所对应的MemMap对象。 */
large_objects_.Put(obj, LargeObject {mem_map, false});
......//其他一些处理,略过
return obj;
}
thread.h
Thread
//虽然tlsPtr_是我们的老熟人了,但它还有一些成员变量的含义在前面的章节中没有介绍
struct PACKED(sizeof(void*)) tls_ptr_sized_values {
......
//下面这个变量表示TLAB上分配了多个对象
size_t thread_local_objects;
//指明TLAB的起始位置
uint8_t* thread_local_start;
/*指明TLAB当前所分配的内存位置,它位于thread_local_start和thread_local_end
之间。[thread_local_start,thead_local_pos)这部分空间属于已经分配的内存,
[thead_local_pos,thread_local_end)这部分为空闲待分配的内存。*/
uint8_t* thread_local_pos;
uint8_t* thread_local_end;//指明TLAB的末尾位置
......
} tlsPtr_;
SetTlab
void Thread::SetTlab(uint8_t* start, uint8_t* end) {
tlsPtr_.thread_local_start = start;
tlsPtr_.thread_local_pos = tlsPtr_.thread_local_start;
tlsPtr_.thread_local_end = end;
tlsPtr_.thread_local_objects = 0;
}
AllocTlab
inline mirror::Object* Thread::AllocTlab(size_t bytes) {
++tlsPtr_.thread_local_objects;
mirror::Object* ret =
reinterpret_cast<mirror::Object*>(tlsPtr_.thread_local_pos);
tlsPtr_.thread_local_pos += bytes;//更新内存水位线即可
return ret;
}
TLAB设计思路