JVM_JIT
JVM解释器和编译器
JVM:JVM有自己完善的硬件架构,如处理器、堆栈(Stack)、寄存器等,还具有相应的指令系统(字节码就是一种指令格式)。JVM屏蔽了与具体操作系统平台相关的信息,使得Java程序只需要生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。JVM是Java平台无关的基础。JVM负责运行字节码:JVM把每一条要执行的字节码交给解释器,翻译成对应的机器码,然后由解释器执行。JVM解释执行字节码文件就是JVM操作Java解释器进行解释执行字节码文件的过程。
Java编译器:将Java源文件(.java文件)编译成字节码文件(.class文件,是特殊的二进制文件,二进制字节码文件),这种字节码就是JVM的“机器语言”。javac.exe可以简单看成是Java编译器。
Java解释器:是JVM的一部分。Java解释器用来解释执行Java编译器编译后的程序。java.exe可以简单看成是Java解释器。
注意:通常情况下,一个平台上的二进制可执行文件不能在其他平台上工作,因为此可执行文件包含了对目标处理器的机器语言。而Class文件这种特殊的二进制文件,是可以运行在任何支持Java虚拟机的硬件平台和操作系统上的!
维基百科定义:
JVM:一种能够运行Java字节码(Java bytecode)的虚拟机。
字节码:字节码是已经经过编译,但与特定机器码无关,需要解释器转译后才能成为机器码的中间代码。
Java字节码:是Java虚拟机执行的一种指令格式。
解释器:是一种电脑程序,能够把高级编程语言一行一行直接翻译运行。解释器不会一次把整个程序翻译出来,只像一位“中间人”,每次运行程序时都要先转成另一种语言再作运行,因此解释器的程序运行速度比较缓慢。它每翻译一行程序叙述就立刻运行,然后再翻译下一行,再运行,如此不停地进行下去。它会先将源码翻译成另一种语言,以供多次运行而无需再经编译。其制成品无需依赖编译器而运行,程序运行速度比较快。
即时编译(Just-in-time compilation: JIT):又叫实时编译、及时编译。是指一种在运行时期把字节码编译成原生机器码的技术,一句一句翻译源代码,但是会将翻译过的代码缓存起来以降低性能耗损。这项技术是被用来改善虚拟机的性能的。
JIT编译器是JRE的一部分。原本的Java程序都是要经过解释执行的,其执行速度肯定比可执行的二进制字节码程序慢。为了提高执行速度,引入了JIT。在运行时,JIT会把翻译过来的机器码保存起来,以备下次使用。而如果JIT对每条字节码都进行编译,则会负担过重,所以,JIT只会对经常执行的字节码进行编译,如循环,高频度使用的方法等。它会以整个方法为单位,一次性将整个方法的字节码编译为本地机器码,然后直接运行编译后的机器码。

编译对象与触发条件
编译对象
程序在运行过程中会被即时编译器编译的「热点代码」有两类:
- 被多次调用的方法;
- 被多次执行的循环体。 这两种被多次重复执行的代码,称之为「热点代码」。
对于被多次调用的方法,方法体内的代码自然会被执行多次,理所当然的就是热点代码。
而对于多次执行的循环体则是为了解决一个方法只被调用一次或者少量几次,但是方法体内部存在循环次数较多的循环体问题,这样循环体的代码也被重复执行多次,因此这些代码也是热点代码。
对于第一种情况,由于是方法调用触发的编译,因此编译器理所当然地会以整个方法作为编译对象,这种编译也是虚拟机中标准的 JIT 编译方式。而对于后一种情况,尽管编译动作是由循环体所触发的,但是编译器依然会以整个方法(而不是单独的循环体)作为编译对象。这种编译方式因为发生在方法执行过程中,因此形象地称之为栈上替换(On Stack Replacement,简称 OSR 编译,即方法栈帧还在栈上,方法就被替换了)。
即时编译器的触发条件
判断一段代码是不是热点代码,是不是需要触发即时编译,这样的行为称为「热点探测」。其实进行热点探测并不一定需要知道方法具体被调用了多少次,目前主要的热点探测判定方式有两种。
-
基于采样的热点探测:采用这种方法的虚拟机会周期性地检查各个线程栈顶,如果发现某个(或某些)方法经常出现在栈顶,那这个方法就是「热点方法」。基于采样的热点探测的好处是实现简单、高效,还可以很容易地获取方法调用关系(将调用栈展开即可),缺点是很难精确地确认一个方法的热度,容易因为受到线程阻塞或别的外界因数的影响而扰乱热点探测。
-
基于计数器的热点探测:采用这种方法的虚拟机会为每个方法(甚至代码块)建立计数器,统计方法的执行次数,如果执行次数超过一定的阈值就认为它是「热点方法」。这种统计方法实现起来麻烦一些,需要为每个方法建立并维护计数器,而且不能直接获取到方法的调用关系,但是统计结果相对来说更加精确和严谨。
HotSpot 虚拟机采用的是第二种:基于计数器的热点探测。因此它为每个方法准备了两类计数器:方法调用计数器(Invocation Counter)和回边计数器(Back Edge Counter)。在确定虚拟机运行参数的情况下,这两个计数器都有一个确定的阈值,当计数器超过阈值就会触发 JIT 编译。
方法调用计数器
顾名思义,这个计数器用于统计方法被调用的次数。当一个方法被调用时,会首先检查该方法是否存在被 JIT 编译过的版本,如果存在,则优先使用编译后的本地代码来执行。如果不存在,则将此方法的调用计数器加 1,==然后判断方法调用计数器与回边计数器之和是否超过方法调用计数器的阈值==。如果超过阈值,将会向即时编译器提交一个该方法的代码编译请求。
如果不做任何设置,执行引擎不会同步等待编译请求完成,而是继续进入解释器按照解释方式执行字节码,直到提交的请求被编译器编译完成。当编译完成后,这个方法的调用入口地址就会被系统自动改写成新的,下一次调用该方法时就会使用已编译的版本。
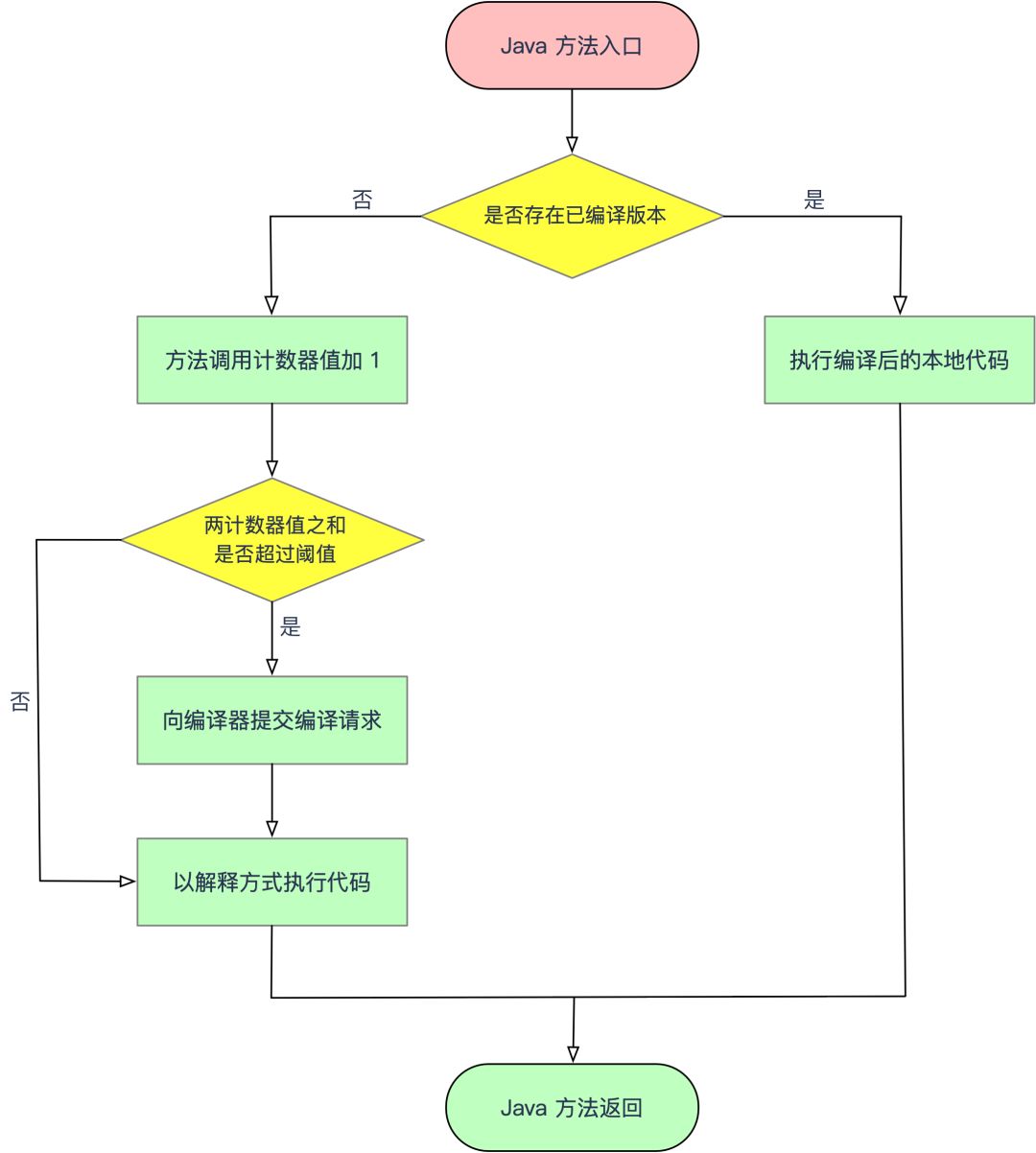
热度衰减
如果不做任何设置,方法调用计数器统计的并不是方法被调用的绝对次数,而是一个相对的执行频率,即一段时间内方法调用的次数。当超过一定的时间限度,如果方法的调用次数仍然不足以让它提交给即时编译器编译,那这个方法的调用计数器值就会被减少一半,这个过程称为方法调用计数器热度的衰减,而这段时间就称为此方法统计的==半衰期==。
进行热度衰减的动作是在虚拟机进行 GC 时顺便进行的,可以设置虚拟机参数来关闭热度衰减,让方法计数器统计方法调用的绝对次数,这样,只要系统运行时间足够长,绝大部分方法都会被编译成本地代码。此外还可以设置虚拟机参数调整半衰期的时间。
回边计数器
回边计数器的作用是统计一个方法中循环体代码执行的次数,在字节码中遇到控制流向后跳转的指令称为「回边」(Back Edge)。建立回边计数器统计的目的是为了触发 OSR 编译。
当解释器遇到一条回边指令时,会先查找将要执行的代码片段是否已经有编译好的版本,如果有,它将优先执行已编译的代码,否则就把回边计数器值加 1,然后判断方法调用计数器和回边计数器值之和是否超过计数器的阈值。当超过阈值时,将会提交一个 OSR 编译请求,并且把回边计数器的值降低一些,以便继续在解释器中执行循环,等待编译器输出编译结果。
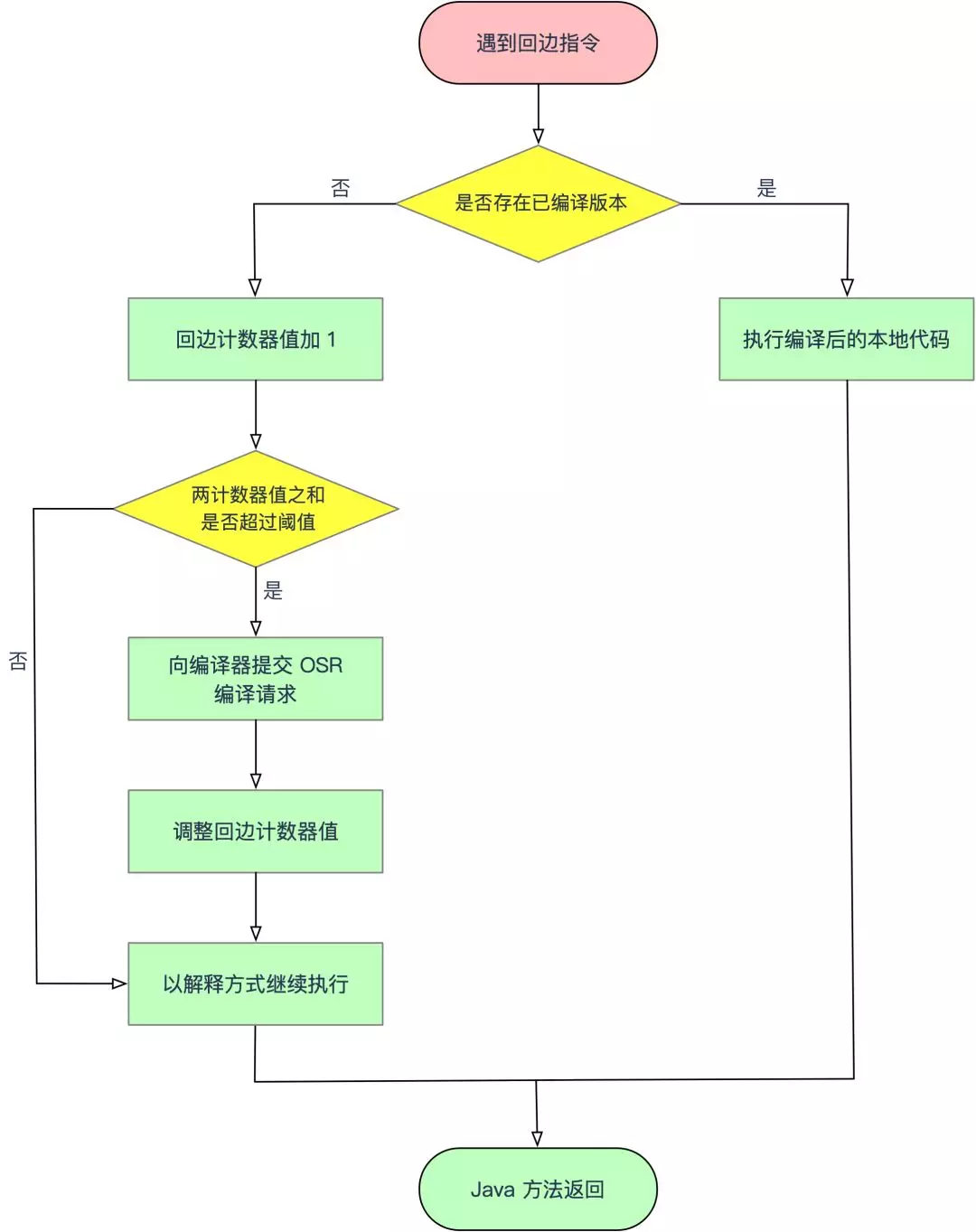
与方法计数器不同,回边计数器没有计算热度衰减的过程,因此这个计数器统计的就是该方法循环执行的绝对次数。当计数器溢出时,它还会把方法计数器的值也调整到溢出状态,这样下次再进入该方法的时候就会执行标准编译过程。
编译优化技术
我们都知道,以编译方式执行本地代码比解释执行方式更快,一方面是因为节约了虚拟机解释执行字节码额外消耗的时间;另一方面是因为虚拟机设计团队几乎把所有对代码的优化措施都集中到了即时编译器中。这一小节我们来介绍下 HotSpot 虚拟机的即时编译器在编译代码时采用的优化技术。
方法内联
第一步是进行方法内联(Method Inlining),方法内联的重要性要高于其它优化措施。方法内联的目的主要有两个,一是去除方法调用的成本(比如建立栈帧),二是为其它优化建立良好的基础,方法内联膨胀之后可以便于更大范围上采取后续的优化手段,从而获得更好的优化效果。因此,各种编译器一般都会把内联优化放在优化序列的最前面
冗余消除
第二步进行冗余消除
复写传播
第三步进行复写传播
无用代码消除
第四步进行无用代码消除
- 公共子表达式消除;
- 数组边界检查消除;
- 方法内联;
- 逃逸分析。
JIT Code Cache
https://docs.oracle.com/javase/8/embedded/develop-apps-platforms/codecache.htm
15 Codecache Tuning This chapter describes techniques for reducing the just-in-time (JIT) compiler’s consumption of memory in the codecache, where it stores compiled methods.
This chapter contains the following topics:
Introduction
java Launcher Codecache Option Summary
Measuring Codecache Usage
Constraining the Codecache Size
Reducing Compilations
Reducing Compiled Method Sizes
Introduction
The Java Virtual Machine (JVM) generates native code and ==stores it in a memory area called the codecache==. The JVM generates native code for a variety of reasons, including for the dynamically generated interpreter loop, Java Native Interface (JNI) stubs, and for Java methods that are compiled into native code by the just-in-time (JIT) compiler. The JIT is by far the biggest user of the codecache. This appendix describes techniques for reducing the JIT compiler’s codecache usage while still maintaining good performance.