2OOM
OOM原因分析
要定位OOM问题,首先需要弄明白Android中有哪些原因会导致OOM,Android中导致OOM的原因主要可以划分为以下几个类型:
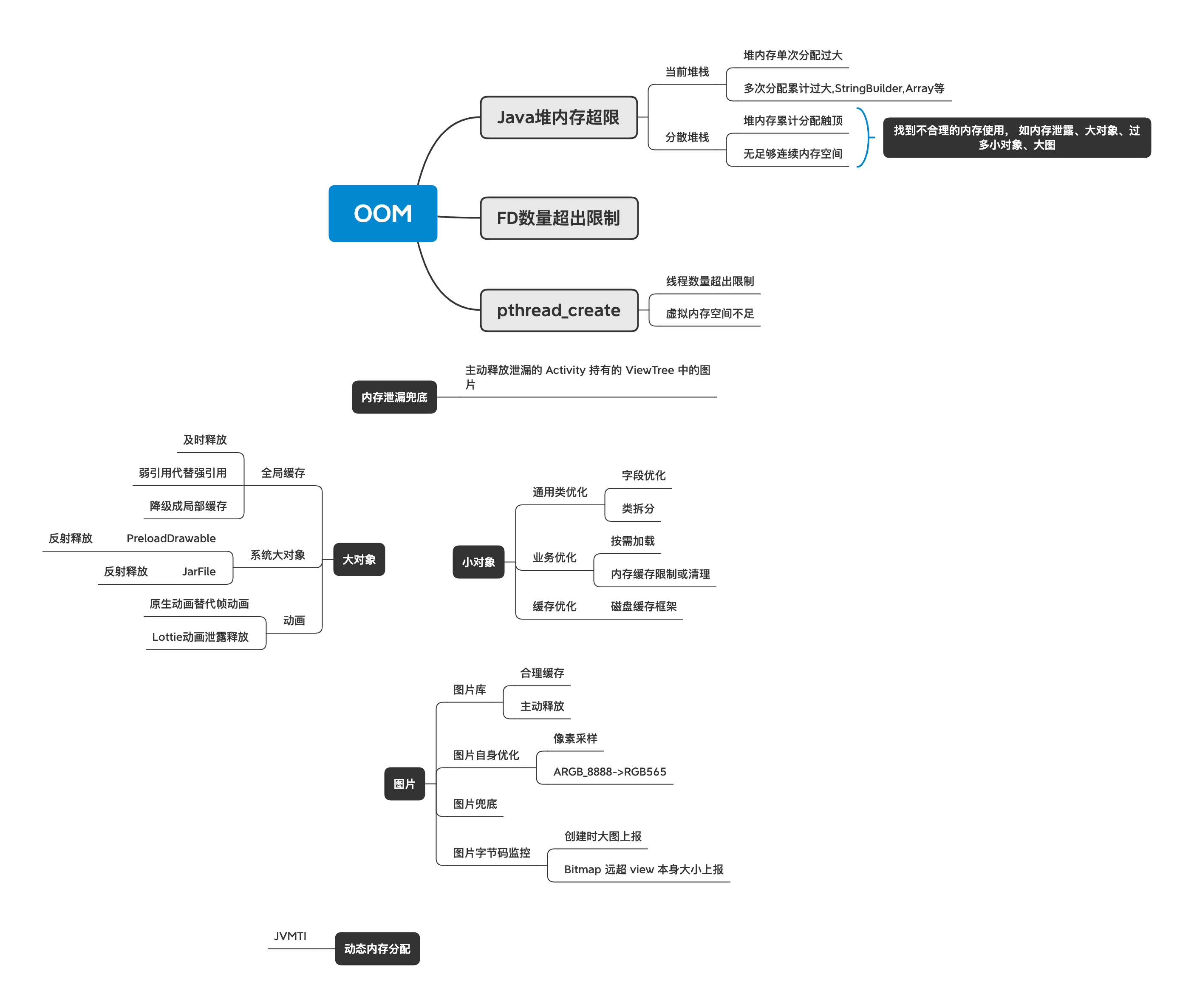
Android 虚拟机最终抛出OutOfMemoryError的代码位于/art/runtime/thread.cc。
void Thread::ThrowOutOfMemoryError(const char* msg)
参数 msg 携带了 OOM 时的错误信息
下面两个地方都会调用上面方法抛出OutOfMemoryError错误,这也是Android中发生OOM的主要原因。
堆内存分配失败
系统源码文件:/art/runtime/gc/heap.cc
void Heap::ThrowOutOfMemoryError(Thread* self, size_t byte_count, AllocatorType allocator_type)
抛出时的错误信息:
oss << "Failed to allocate a " << byte_count << " byte allocation with " << total_bytes_free << " free bytes and " << PrettySize(GetFreeMemoryUntilOOME()) << " until OOM";
这是在进行堆内存分配时抛出的OOM错误,这里也可以细分成两种不同的类型:
- 为对象分配内存时达到进程的内存上限。由Runtime.getRuntime.MaxMemory()可以得到Android中每个进程被系统分配的内存上限,当进程占用内存达到这个上限时就会发生OOM,这也是Android中最常见的OOM类型。
- 没有足够大小的连续地址空间。这种情况一般是进程中存在大量的内存碎片导致的,其堆栈信息会比第一种OOM堆栈多出一段信息:failed due to fragmentation (required continguous free “« required_bytes « “ bytes for a new buffer where largest contiguous free ” « largest_continuous_free_pages « “ bytes)”; 其详细代码在art/runtime/gc/allocator/rosalloc.cc中,这里不作详述。
创建线程失败
系统源码文件:/art/runtime/thread.cc
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon)
抛出时的错误信息:
"Could not allocate JNI Env"
或者
StringPrintf("pthread_create (%s stack) failed: %s", PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
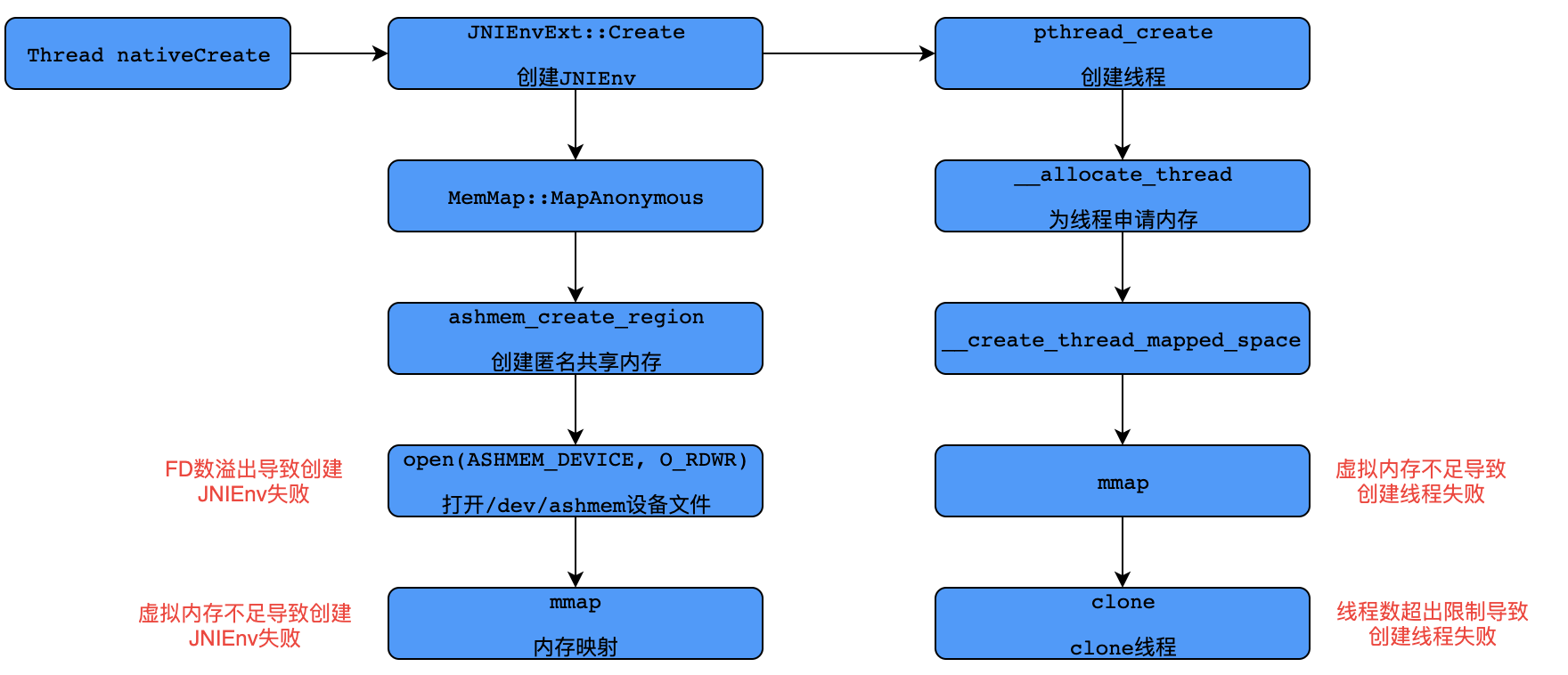
这是创建线程时抛出的OOM错误,且有多种错误信息。源码这里不展开详述了,下面是根据源码整理的Android中创建线程的步骤,其中两个关键节点是创建JNIEnv结构体和创建线程,而这两步均有可能抛出OOM。
创建JNI失败
创建JNIEnv可以归为两个步骤:
- 通过Andorid的匿名共享内存(Anonymous Shared Memory)分配 4KB(一个page)内核态内存。
- 再通过Linux的mmap调用映射到用户态虚拟内存地址空间。
第一步创建匿名共享内存时,需要打开/dev/ashmem文件,所以需要一个FD(文件描述符)。此时,如果创建的FD数已经达到上限,则会导致创建JNIEnv失败,抛出错误信息如下:
E/art: ashmem_create_region failed for 'indirect ref table': Too many open files
java.lang.OutOfMemoryError: Could not allocate JNI Env
at java.lang.Thread.nativeCreate(Native Method)
at java.lang.Thread.start(Thread.java:730)
第二步调用mmap时,如果进程虚拟内存地址空间耗尽,也会导致创建JNIEnv失败,抛出错误信息如下:
E/art: Failed anonymous mmap(0x0, 8192, 0x3, 0x2, 116, 0): Operation not permitted. See process maps in the log.
java.lang.OutOfMemoryError: Could not allocate JNI Env
at java.lang.Thread.nativeCreate(Native Method)
at java.lang.Thread.start(Thread.java:1063)
创建线程失败
创建线程也可以归纳为两个步骤:
- 调用mmap分配栈内存。这里mmap flag中指定了MAP_ANONYMOUS,即匿名内存映射。这是在Linux中分配大块内存的常用方式。其分配的是虚拟内存,对应页的物理内存并不会立即分配,而是在用到的时候触发内核的缺页中断,然后中断处理函数再分配物理内存。
- 调用clone方法进行线程创建。
第一步分配栈内存失败是由于进程的虚拟内存不足,抛出错误信息如下:
W/libc: pthread_create failed: couldn't allocate 1073152-bytes mapped space: Out of memory
W/tch.crowdsourc: Throwing OutOfMemoryError with VmSize 4191668 kB "pthread_create (1040KB stack) failed: Try again"
java.lang.OutOfMemoryError: pthread_create (1040KB stack) failed: Try again
at java.lang.Thread.nativeCreate(Native Method)
at java.lang.Thread.start(Thread.java:753)
第二步clone方法失败是因为线程数超出了限制,抛出错误信息如下:
W/libc: pthread_create failed: clone failed: Out of memory
W/art: Throwing OutOfMemoryError "pthread_create (1040KB stack) failed: Out of memory"
java.lang.OutOfMemoryError: pthread_create (1040KB stack) failed: Out of memory
at java.lang.Thread.nativeCreate(Native Method)
at java.lang.Thread.start(Thread.java:1078)
线程监控
常见的 OOM 情况大多数是因为内存泄漏或申请大量内存造成的,比较少见的有下面这种跟线程相关情况,但在我们 crash 系统上有时能发现一些这样的问题。
java.lang.OutOfMemoryError: pthread_create (1040KB stack) failed: Out of memory
原因分析
OutOfMemoryError 这种异常根本原因在于申请不到足够的内存造成的,直接的原因是在创建线程时初始 stack size 的时候,分配不到内存导致的。这个异常是在 /art/runtime/thread.cc 中线程初始化的时候 throw 出来的。
void Thread::CreateNativeThread(JNIEnv* env, jobject java_peer, size_t stack_size, bool is_daemon) {
...
int pthread_create_result = pthread_create(
&new_pthread, &attr, Thread::CreateCallback, child_thread);
if (pthread_create_result != 0) {
env->SetLongField(java_peer, WellKnownClasses::java_lang_Thread_nativePeer, 0);
{
std::string msg(StringPrintf("pthread_create (%s stack) failed: %s",
PrettySize(stack_size).c_str(), strerror(pthread_create_result)));
ScopedObjectAccess soa(env);
soa.Self()->ThrowOutOfMemoryError(msg.c_str());
}
}
}
调用这个 pthread_create 的方法去 clone 一个线程,如果返回 pthread_create_result 不为 0,则代表初始化失败。什么情况下会初始化失败,pthread_create 的具体逻辑是在 /bionic/libc/bionic/pthread_create.cpp 中完成:
int pthread_create(pthread_t* thread_out, pthread_attr_t const* attr,
void* (*start_routine)(void*), void* arg) {
...
pthread_internal_t* thread = NULL;
void* child_stack = NULL;
int result = __allocate_thread(&thread_attr, &thread, &child_stack);
if (result != 0) {
return result;
}
...
}
static int __allocate_thread(pthread_attr_t* attr, pthread_internal_t** threadp, void** child_stack) {
size_t mmap_size;
uint8_t* stack_top;
...
attr->stack_base = __create_thread_mapped_space(mmap_size, attr->guard_size);
if (attr->stack_base == NULL) {
return EAGAIN; // EAGAIN != 0
}
...
return 0;
}
可以看到每个线程初始化都需要 mmap 一定的 stack size,在默认的情况下一般初始化一个线程需要 mmap 1M 左右的内存空间,在 32bit 的应用中有 4g 的 vmsize,实际能使用的有 3g+,按这种估算,一个进程最大能创建的线程数可达 3000+,当然这是理想的情况,在 linux 中对每个进程可创建的线程数也有一定的限制(/proc/pid/limits)而实际测试中,我们也发现不同厂商对这个限制也有所不同,而且当超过系统进程线程数限制时,同样会抛出这个类型的 OOM。
可见对线程数量的限制,可以一定程度避免 OOM 的发生。所以我们也开始对微信的线程数进行了监控统计。
监控上报
我们在灰度版本中通过一个定时器 10 分钟 dump 出应用所有的线程,当线程数超过一定阈值时,将当前的线程上报并预警,通过对这种异常情况的捕捉,我们发现微信在某些特殊场景下,确实存在线程泄漏以及短时间内线程暴增,导致线程数过大(500+)的情况,这种情况下再创建线程往往容易出现 OOM。
在定位并解决这几个问题后,我们的 crash 系统和厂商的反馈中这种类型 OOM 确实降低了不少。所以监控线程数,收敛线程也成为我们降低 OOM 的有效手段之一。
堆内存不足
Android中最常见的OOM就是Java堆内存不足,对于堆内存不足导致的OOM问题,发生Crash时的堆栈信息往往只是“压死骆驼的最后一根稻草”,它并不能有效帮助我们准确地定位到问题。
堆内存分配失败,通常说明进程中大部分的内存已经被占用了,且不能被垃圾回收器回收,一般来说此时内存占用都存在一些问题,例如内存泄漏等。要想定位到问题所在,就需要知道进程中的内存都被哪些对象占用,以及这些对象的引用链路。而这些信息都可以在Java内存快照文件中得到,调用Debug.dumpHprofData(String fileName)函数就可以得到当前进程的Java内存快照文件(即HPROF文件)。所以,关键在于要获得进程的内存快照,由于dump函数比较耗时,在发生OOM之后再去执行dump操作,很可能无法得到完整的内存快照文件。
线上分析
首先,我们介绍几个基本概念:
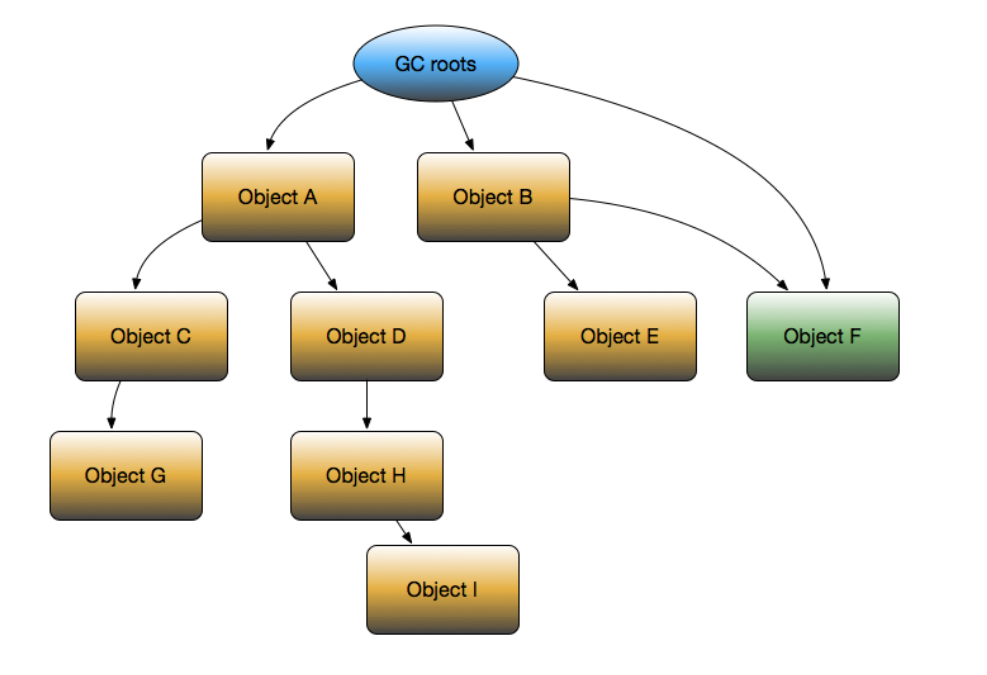
- Dominator:从GC Roots到达某一个对象时,必须经过的对象,称为该对象的Dominator。例如在上图中,B就是E的Dominator,而B却不是F的Dominator。Dominator用于计算RetainSize,一旦object的dominator被释放,那么自身也会被释放。上图黄色node为dominator tree
- ShallowSize:对象自身占用的内存大小,不包括它引用的对象。
- RetainSize:对象自身的ShallowSize和对象所支配的(可直接或间接引用到的)对象的ShallowSize总和,就是该对象GC之后能回收的内存总和。例如上图中,D的RetainSize就是D、H、I三者的ShallowSize之和。
Object Reference graph to Dominator Tree Conversion
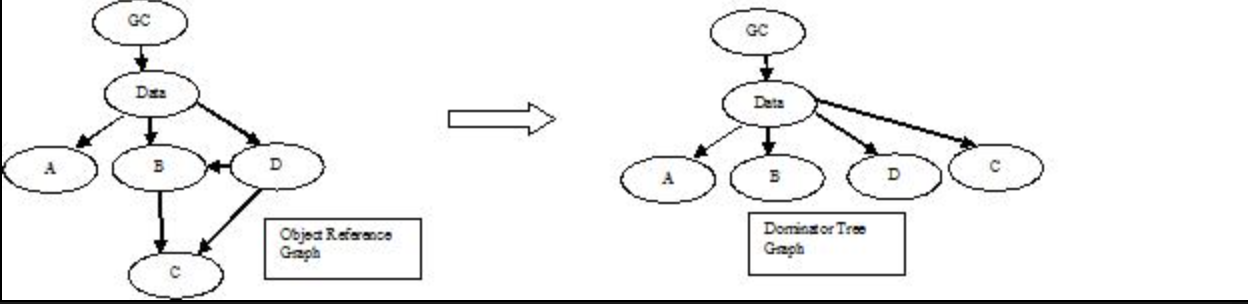
JVM在进行GC的时候会进行可达性分析,当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是可回收的。
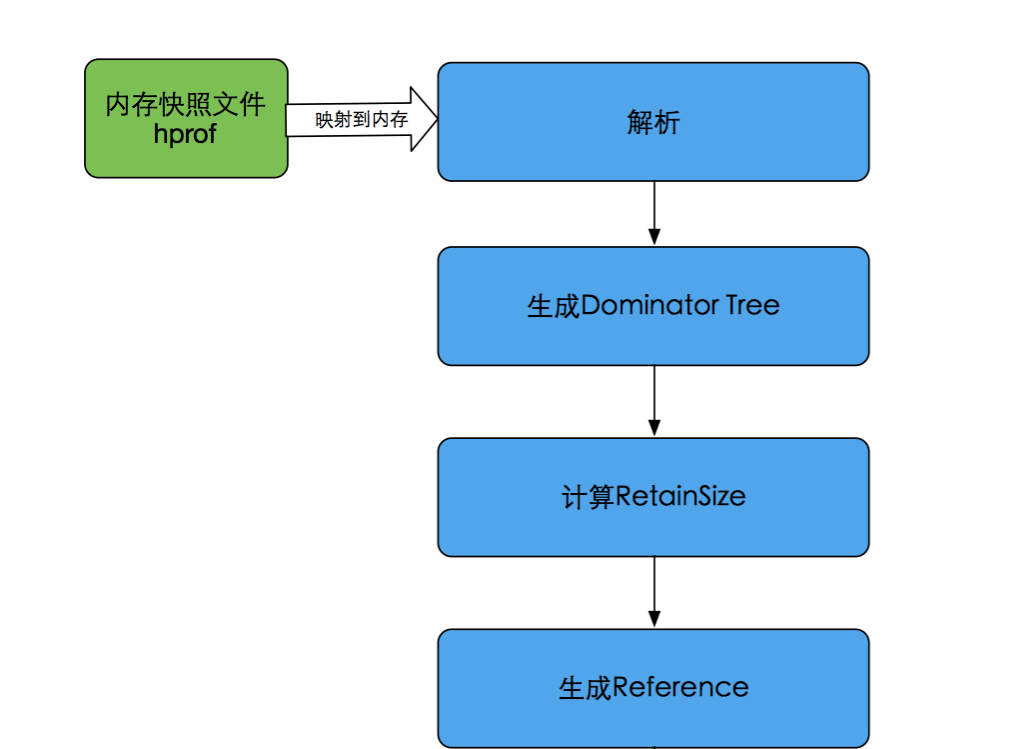
Github上有一个开源项目HAHA库,用于自动解析和分析Java内存快照文件(即HPROF文件)。下面是HAHA库的分析步骤:
HAHA库
退出率定义
经过认真思考,我们认识到从前忽略了一个重要的基本事实,即应用的启动数和应用的退出数是守恒的。每次启动必然会有对应的退出,只要将所有的退出类型都枚举出来并监控上报,且总数能和启动数吻合,就能覆盖所有的稳定性问题。 基于以上思想,我们提出了退出率的概念,将退出分为以下十大类,每一类的退出率定义为 退出次数 / 启动次数。

图4
其中前五种退出类型是显著影响用户体验的问题,需要重点关注,crash(不含OOM)和OOM对应的是开头提到的通用指标;前台系统强杀指的是设备总内存紧张,应用在前台被系统强杀,比如iOS的jetsam,android的low memory killer,也包括其他一些资源问题,比如上文讲的wakeups;watchdog指的是卡顿引起的系统强杀,典型的即为iOS的watchdog和android的ANR;exit指的是我们主动在代码中自杀,通常情况下不应该有这样的逻辑存在。后五种退出类型绝大多数情况下是正常的退出行为,对用户体验无影响,我们只关注其中异常的情况,比如UI错乱导致的用户强杀,危险代码导致的系统重启等。
Android OOM治理
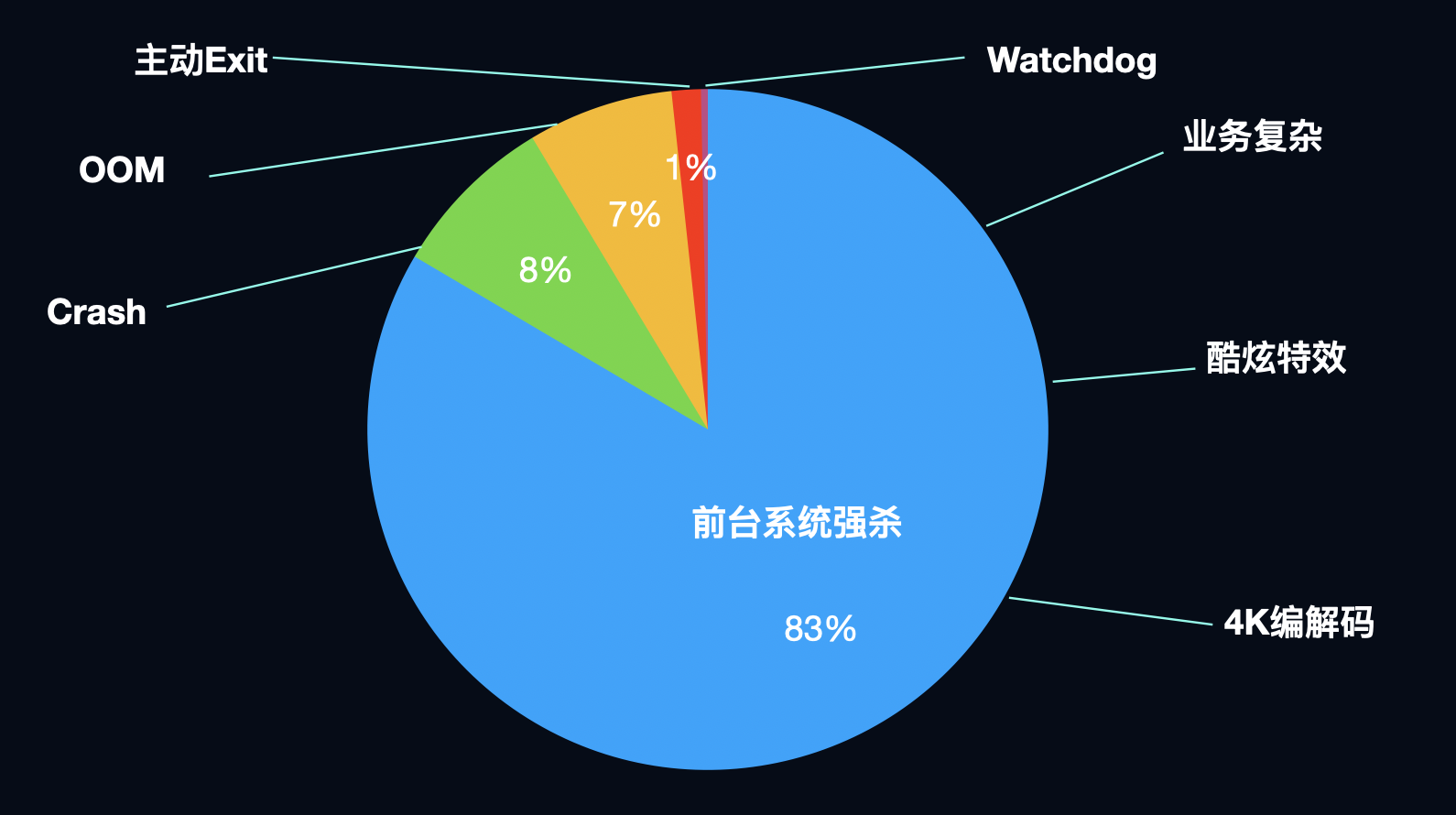
图9
回顾前文,OOM在稳定性重点关注问题中的占比非常高,和占比最高的前台系统强杀也有很高的相关性,而OOM问题的定位又特别困难,通常需要投入大量的人力和时间,进行人工复现,灰度收集数据,提交记录二分法暴力验证等等。占比高又定位困难,可以说OOM治理是稳定性治理皇冠上的明珠。 提到OOM,肯定绕不开神器LeakCanary,其原理也是面试题中的常客,作为Android内存泄漏监控的开创者,多年来一直为广大app保驾护航,解决了OOM治理从0到1的问题。那么直接接入LeakCanary上线不香么?还真不行,LeakCanary虽然非常优秀,但也存在以下几点硬伤:
- 无法线上部署
- 主动触发GC,造成卡顿
- Dump内存镜像造成app冻结
- 解析镜像成功率低
- 不具备上报能力
- 适用范围有限
- 只能定位Activity&Fragment泄漏
- 无法定位大对象、频繁分配等问题
- 自动化程度低
- 需要人工埋点
- 无法对问题聚类
既然没有现成的轮子可用,只能自己动手,丰衣足食,经过一番努力,我们打造了一套可以线上部署、兼顾线下、配置灵活、适用范围广泛、高度自动化,埋点、监控、解析、上报、分发、跟进、报警一站式服务的闭环监控系统。
核心流程图解
graph LR
subgraph 解析单一引用链
LeakCanary3
end
subgraph 解析大量引用链
KOOM3
end
监控模块-->LeakCannary1("LeakCannary")-->泄露发生实时,主动触发GC,会造成卡顿
监控模块-->KOOM-->内存阈值监控-->Java堆内存/线程数/文件描述符数突破阈值触发采集
内存阈值监控-->Java堆上涨速度突破阈值触发采集
内存阈值监控-->发生OOM时如果策略1,2未命中,触发采集
内存阈值监控-->泄漏判定延迟至解析时
采集模块-->LeakCannary2("LeakCannary")-->主进程DumpHprof,会造成app冻结
LeakCannary2-->Hprof文件过大
采集模块-->KOOM2("KOOM")-->Fork子进程DumpHprof,提前suspendAllThreads
KOOM2-->HookWrite实时裁剪Hprof
解析模块-->LeakCanary3("LeakCannary")-->解析耗时过长
解析模块-->KOOM3("KOOM")-->客户端解析
KOOM3-->关键对象判定-->泄露
关键对象判定-->shallow/retainedSize超过阈值
KOOM3-->性能优化-->内存懒加载,存储对象在hprof中的位置,并为其建立索引方便按需解析
性能优化-->SortedBytesMap
性能优化-->类型剪枝,同类对象超过阈值不再搜索,缓存每个类的superClass,objectID类型从long改为int
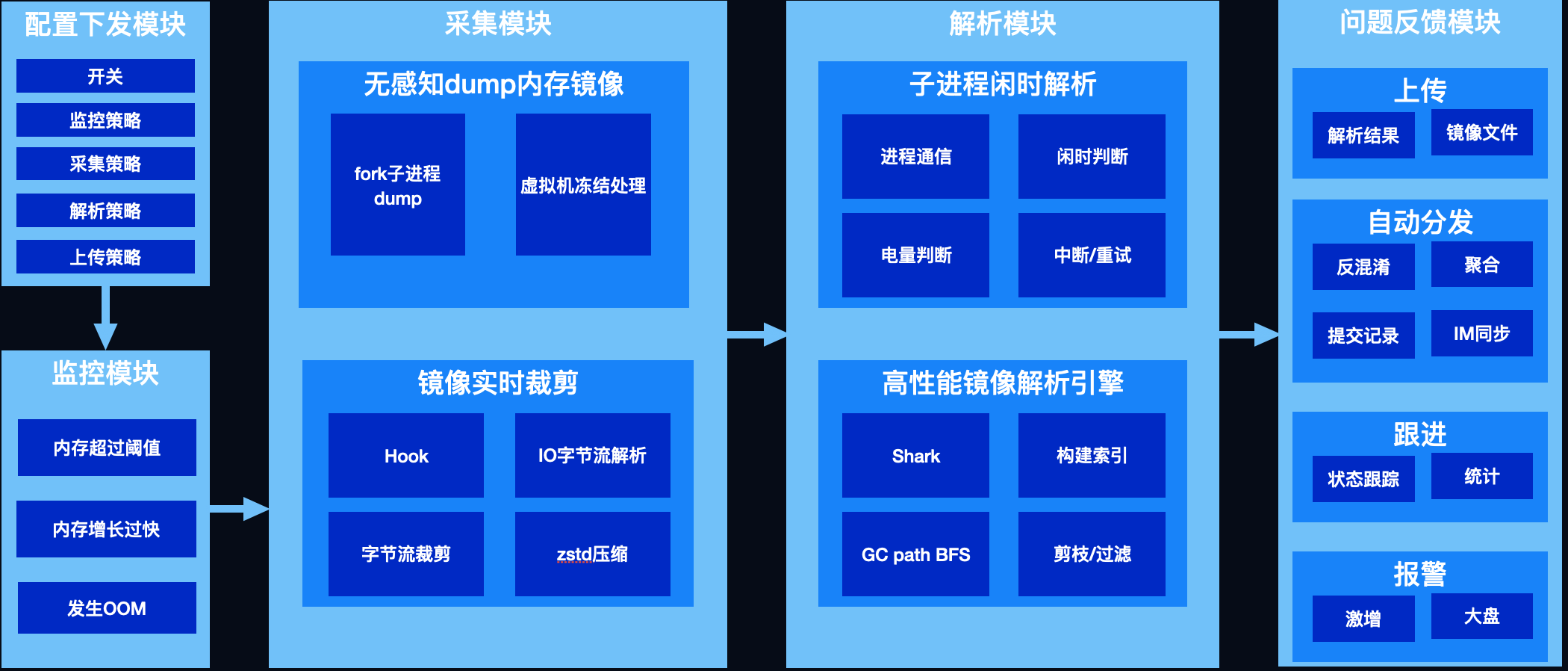
其核心流程为三部分:
- 监控OOM,发生问题时触发内存镜像的采集,以便进一步分析问题
- 采集内存镜像,学名堆转储,将内存数据拷贝到文件中,以下简称dump hprof
- 解析镜像文件,对泄漏、超大对象等我们关注的对象进行可达性分析,解析出其到GC root的引用链以解决问题
为完成这样一套监控系统,我们攻克了以下技术难题
- 监控
- 主动触发GC,会造成卡顿
- 采集
- Dump hprof,会造成app冻结
- Hprof文件过大
- 解析
- 解析耗时过长
- 解析本身有OOM风险
接下来我们一一展开分析。
解决GC卡顿
为什么LeakCanary需要主动触发GC呢?LeakCanary监控泄漏利用了弱引用的特性,为Activity创建弱引用,当Activity对象变成弱可达时(没有强引用),弱引用会被加入到引用队列中,通过在Activity.onDestroy()后连续触发两次GC,并检查引用队列,可以判定Activity是否发生了泄漏。但频繁的GC会造成用户可感知的卡顿,为解决这一问题,我们设计了全新的监控模块,通过无性能损耗的内存阈值监控来触发镜像采集,具体策略如下:
- Java堆内存/线程数/文件描述符数突破阈值触发采集
- Java堆上涨速度突破阈值触发采集
- 发生OOM时如果策略1、2未命中 触发采集
- 泄漏判定延迟至解析时
阈值监控只要在子线程定期获取关注的几个内存指标即可,性能损耗可以忽略不计;内存快速上涨用来定位对象频繁分配的问题;OOM作为最后兜底的策略,走到这里说明我们的阈值设计有漏洞,没有拦截住所有可能触发OOM的场景;最后,我们将对象是否泄漏的判断延迟到了解析时。还是以Activity为例,我们并不需要在运行时判定其是否泄漏,Activity有一个成员变mDestroyed,在onDestory时会被置为true,只要解析时发现有可达且mDestroyed为true的Activity,即可判定为泄漏(由于时序问题,这里可能有极小概率会发生误判,但不影响我们解决问题),其他关注的对象可以根据其特点设计规则。用一张图总结:
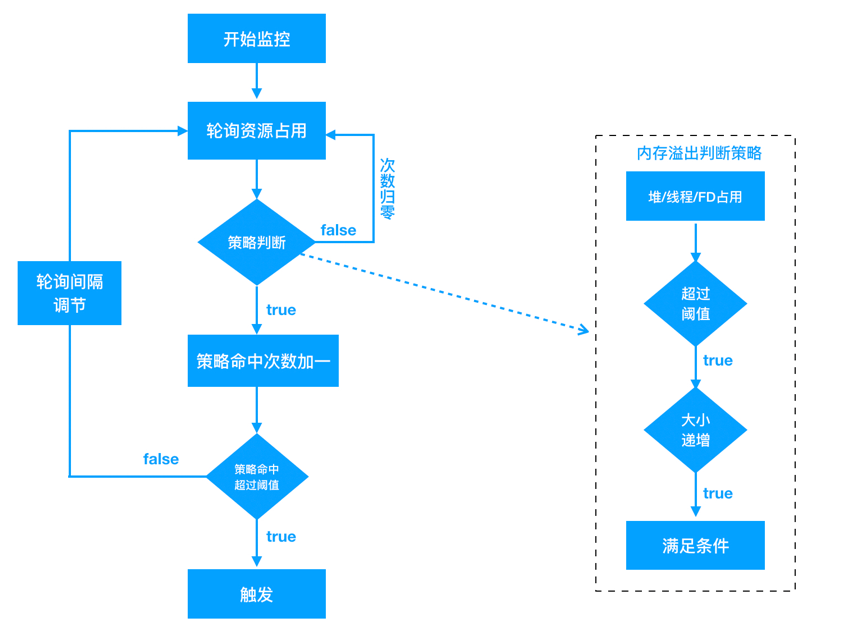
图11
解决Dump hprof冻结app
Dump hprof是通过虚拟机提供的API dumpHprofData实现的,这个过程会**“冻结”**整个应用进程,造成数秒甚至数十秒内用户无法操作,这也是LeakCanary无法线上部署的最主要原因,如果能将这一过程优化至用户无感知,将会给OOM治理带来很大的想象空间。
面对这样一个问题,我们将其拆解,自然而然产生2个疑问: 1.为什么dumpHprofData会冻结app,虚拟机的实现原理是什么? 2.这个过程能异步吗? 我们来看dumpHprofData的虚拟机内部实现 art/runtime/hprof/hprof.cc
// If "direct_to_ddms" is true, the other arguments are ignored, and data is sent directly to DDMS.
// If "fd" is >= 0, the output will be written to that file descriptor.
// Otherwise, "filename" is used to create an output file.
void DumpHeap(const char* filename, int fd, bool direct_to_ddms) {
CHECK(filename != nullptr);
Thread* self = Thread::Current();
// Need to take a heap dump while GC isn't running. See the comment in Heap::VisitObjects().
// Also we need the critical section to avoid visiting the same object twice. See b/34967844
gc::ScopedGCCriticalSection gcs(self,
gc::kGcCauseHprof,
gc::kCollectorTypeHprof);
ScopedSuspendAll ssa(__FUNCTION__, true /* long suspend */);
Hprof hprof(filename, fd, direct_to_ddms);
hprof.Dump();
}
可以看到在dump前,通过ScopedSuspendAll(构造函数中执行SuspendAll)执行了暂停所有java线程的操作,以防止在dump的过程中java堆发生变化,当dump结束后通过ScopedSuspendAll析构函数进行ResumeAll。
解决了第一个问题,接下来看第二个问题,既然要冻结所有线程,子线程异步处理是没有意义的,那么在子进程中处理呢?Android的内核是定制过的Linux, 而Linux fork子进程有一个著名的COW(Copy-on-write,写时复制)机制,即为了节省fork子进程的内存消耗和耗时,fork出的子进程并不会copy父进程的内存,而是和父进程共享内存空间。那么如何做到进程隔离呢,父子进程只在发生内存写入操作时,系统才会分配新的内存为写入方保留单独的拷贝,这就相当于子进程保留了fork瞬间时父进程的内存镜像,且后续父进程对内存的修改不会影响子进程,想到这里我们豁然开朗。说干就干,我们写了一个demo来验证这个思路,很快就遇到了棘手的新问题:dump前需要暂停所有java线程,而子进程只保留父进程执行fork操作的线程,在子进程中执行SuspendAll触发暂停是永远等不到其他线程返回结果的(详见thread_list.cc中行SuspendAll的实现,这里不展开讲了),经过仔细分析SuspendAll的过程,我们发现,可以先在主进程执行SuspendAll,使ThreadList中保存的所有线程状态为suspend,之后fork,子进程共享父进程的ThreadList全局变量,可以欺骗虚拟机,使其以为全部线程已经完成了暂停操作,接下来子进程就可以愉快的dump hprof了,而父进程可以立刻执行ResumeAll恢复运行。
这里有一个小技巧,SuspendAll没有对外暴露Java层的API,我们可以通过C层间接暴露的art::Dbg::SuspendVM来调用,dlsym拿到“_ZN3art3Dbg9SuspendVMEv”的地址调用即可,ResumeAll同理,注意这个函数在android 11以后已经被去除了,需要另行适配。Android 7之后对linker做了限制(即dlopen系统库失效),快手自研了kwai-linker组件,通过caller address替换和dl_iterate_phdr解析绕过了这一限制。 至此,我们完美解决了dump hprof冻结app的问题,用一张图总结:
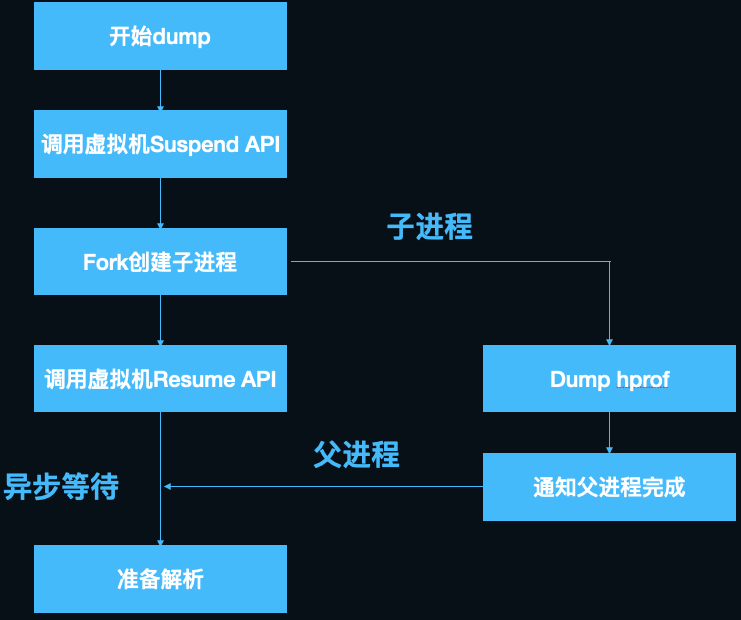
图12
解决hprof文件过大
Hprof文件通常比较大,分析OOM时遇到500M以上的hprof文件并不稀奇,文件的大小,与dump成功率、dump速度、上传成功率负相关,且大文件额外浪费用户大量的磁盘空间和流量。我们因此想到了对hprof进行裁剪,只保留分析OOM必须的数据,另外,裁剪还有数据脱敏的好处,只上传内存中类与对象的组织结构,并不上传真实的业务数据(诸如字符串、byte数组等含有具体数据的内容),保护用户隐私。
开发镜像裁剪,有两个衡量指标:一是裁剪率,即在不影响问题分析的前提下,裁剪掉的内容要足够多;二是裁剪性能损耗,如果性能不达标引发耗电、成功率低引入新的问题,就会使得内存镜像获取得不偿失。
照例,我们将问题拆解:
- hprof存的内容都是些什么?数据如何组织的?哪些可以裁掉?
- 内存中的数据结构和hprof文件二进制协议的映射关系?
- 如何裁剪?
想要了解hprof的数据组织方式,推荐阅读openjdk官方文档[2],Android在此基础上做了一些扩展,这里简要介绍一下核心内容:
- 文件按byte by byte顺序存储,u1,u2,u4分别代表1字节,2字节,4字节。
- 总体分为两部分,
Header和Record,Header记录hprof的元信息,Record分很多条目,每一条有一个单独的TAG代表类型。
我们关注的Record类型主要是HEAP DUMP,其中又分五个子类,分别为GC ROOT、CLASS DUMP、INSTANCE DUMP、OBJECT ARRAY DUMP、PRIMITIVE ARRAY DUMP。图13以PRIMITIVE ARRAY DUMP(基本类型数组)为例展示Record中包含的信息,其他类型请查阅官方文档。内存中绝大部分数据是PRIMITIVE ARRAY DUMP,通常占据80%以上,而我们分析OOM只关系对象的大小和引用关系,并不关心内容,因此这部分是我们裁剪的突破口。

图13
Android对数据类型做了扩展,增加了一些GC ROOT
// Android.
HPROF_HEAP_DUMP_INFO = 0xfe,
HPROF_ROOT_INTERNED_STRING = 0x89,
HPROF_ROOT_FINALIZING = 0x8a, // Obsolete.
HPROF_ROOT_DEBUGGER = 0x8b,
HPROF_ROOT_REFERENCE_CLEANUP = 0x8c, // Obsolete.
HPROF_ROOT_VM_INTERNAL = 0x8d,
HPROF_ROOT_JNI_MONITOR = 0x8e,
HPROF_UNREACHABLE = 0x90, // Obsolete.
HPROF_PRIMITIVE_ARRAY_NODATA_DUMP = 0xc3, // Obsolete.
还有一个HEAP_DUMP_INFO,这里面保存的是堆空间(heap space)的类型,Android对堆空间做了划分,我们只关注HPROF_HEAP_APP即可,其余也是可以裁剪掉的,可以参考Android Studio中Memory Profiler的处理[3]。
enum HprofHeapId {
HPROF_HEAP_DEFAULT = 0,
HPROF_HEAP_ZYGOTE = 'Z',
HPROF_HEAP_APP = 'A',
HPROF_HEAP_IMAGE = 'I',
};
接下来讨论如何裁剪,裁剪有两种办法,第一种是在dump完成后的hprof文件基础上裁剪,性能比较差,对磁盘空间要求也比较高,第二种是在dump的过程中实时裁剪,我们自然想要实现第二种。看一下Record写入的过程,先执行StartNewRecord,然后通过AddU1/U4/U8写入内存buffer,最后执行EndRecord将buffer写入文件。
void StartNewRecord(uint8_t tag, uint32_t time) {
if (length_ > 0) {
EndRecord();
}
DCHECK_EQ(length_, 0U);
AddU1(tag);
AddU4(time);
AddU4(0xdeaddead); // Length, replaced on flush.
started_ = true;
}
void EndRecord() {
// Replace length in header.
if (started_) {
UpdateU4(sizeof(uint8_t) + sizeof(uint32_t),
length_ - sizeof(uint8_t) - 2 * sizeof(uint32_t));
}
HandleEndRecord();
sum_length_ += length_;
max_length_ = std::max(max_length_, length_);
length_ = 0;
started_ = false;
}
void HandleFlush(const uint8_t* buffer, size_t length) override {
if (!errors_) {
errors_ = !fp_->WriteFully(buffer, length);
}
}
这个过程中有两个hook点可以选择,一是hook AddUx,在写入buffer的过程中裁剪,二是hook write,在写入文件过程中裁剪。最终我们选择了方案二,理由是AddUx调用比较频繁,判断逻辑复杂容易出现兼容性问题,而write是public API,且只在Record写入文件的时候调用一次,厂商不会魔改相关实现,从hook原理上来讲,hook外部调用的PLT/GOT hook也比hook内部调用的inline hook要稳定得多。
用一张图总结裁剪的流程:
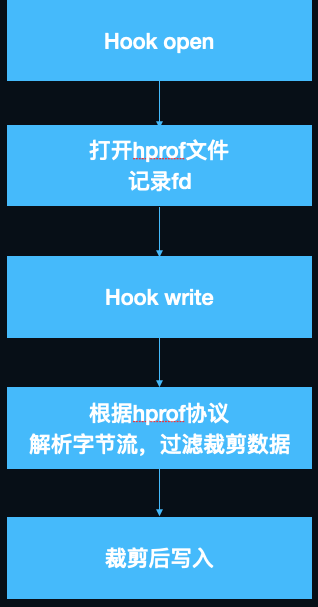
图14
解决hprof解析的耗时与OOM
解析hprof文件,对关键对象进行可达性分析,得到引用链,是我们解决OOM最核心的一步,之前的监控和dump都是为解析做铺垫。解析分两种,一种是上传hprof文件由server解析,另一种是在客户端解析后上传报告(通常只有几KB)。最终我们选择了端上解析,这样做有两个好处:
- 节省用户流量
- 利用用户闲时算力,降低server压力,这样也符合分布式计算理念。
照例,我们依然将问题拆解:
- 哪些对象需要分析,全部分析性能开销太大,很难在端上完成,并且问题没有重点也不利于解决。
- 性能优化,作为一个debug组件,要在不影响用户体验的情况下完成解析,对性能有非常高的要求。
关键对象判定
回顾前文,我们只解析关键对象的引用链,并写入分析报告中上传,判定的准确性和覆盖度决定了分析的质量。
我们将关键对象分为两类,一类是根据规则可以判断出对象已经泄露,且持有大量资源的,另外一类是对象shallow / retained size 超过阈值。
Activity/fragment泄露判定即为第一种: 对于强可达的activity对象,其mDestroyed值为true时(onDestroy时赋值),判定已经泄露。类似的,对于fragment,当mCalled值为true且mFragmentManager为null时,判定已经泄露 。 我们可以用同样的思路合理制定规则,来处理我们核心的业务组件,比如无处不在的presenter。
Bitmap/window/array/sufacetexture判定为第二种 检查bitmap/texture的数量、宽高、window数量、array长度等等是否超过阈值,再结合hprof中的相关业务信息,比如屏幕大小,view大小等进行判定。
性能优化
一开始我们尝试了LeakCanary的解析引擎HAHA(Android Studio解析引擎perlib的Android移植版),解析过程中非常容易OOM,且解析速度极慢,500M的hprof文件,内存峰值达到2G,绝大多数Andriod设备的Java堆内存上限只有512M,即使顶配的macbook解析耗时都在3分钟以上,如此性能,在端上解析成功率低到发指。一度使我们想放弃现有的轮子,用C重写解析库,恰好此时LeakCanary发布了新的解析引擎shark[4],号称内存峰值可以降低10倍,解析速度可以提升6倍。我们实验了一下,发现小的demo hprof基本能达到其宣称的性能,线上真实环境拿到的包含百万级对象hprof文件,性能会急剧下降,分析时间突破10分钟。因此,我们需要进一步优化,优化之前,先来研究一下HAHA和shark的原理。
为什么HAHA内存峰值高,速度慢呢,概括起来主要是以下几点:
- 没做懒加载,hprof内容全部load到内存里。
domanitor tree[5]全量计算,实际上我们只关心关键对象的retained size。- 频繁触发GC,java的集合类没有针对计算密集型任务做优化,含有大量冗余的装箱、拆箱、扩容、拷贝等操作,大量创建对象,频繁触发GC,GC反过来进一步降低对象分配速度,陷入恶性循环。
Shark是如何优化的呢? Shark是LeakCanary 2.0推出的全新解析组件,其设计思想详见作者的介绍[6],主要做了以下几项优化:
- 索引,
shark低内存开销的最根本原因就是通过索引做到了内存懒加载,遍历hprof时存储对象在hprof中的位置,并为其建立索引方便按需解析。 - 数据结构上做了深度优化,主要是使用了更高效的
map,有2个:第一是对于key和value都是基础类型或字符串的使用hppc做map,第二是对于value不是基本类型的,使用SortedBytesMap存储内容。
具体的索引有:实例索引、类索引、字符串索引、类名索引、数组索引:
/**
* This class is not thread safe, should be used from a single thread.
*/
internal class HprofInMemoryIndex private constructor(
private val positionSize: Int,
private val hprofStringCache: LongObjectScatterMap<String>,
private val classNames: LongLongScatterMap,
private val classIndex: SortedBytesMap,
private val instanceIndex: SortedBytesMap,
private val objectArrayIndex: SortedBytesMap,
private val primitiveArrayIndex: SortedBytesMap,
private val gcRoots: List<GcRoot>,
private val proguardMapping: ProguardMapping?,
val primitiveWrapperTypes: Set<Long>
) {
/**
* Code from com.carrotsearch.hppc.LongLongScatterMap copy pasted, inlined and converted to Kotlin.
*
* See https://github.com/carrotsearch/hppc .
*/
class LongLongScatterMap constructor(expectedElements: Int = 4) {
/**
* A read only map of `id` => `byte array` sorted by id, where `id` is a long if [longIdentifiers]
* is true and an int otherwise. Each entry has a value byte array of size [bytesPerValue].
*
* Instances are created by [UnsortedByteEntries]
*
* [get] and [contains] perform a binary search to locate a specific entry by key.
*/
internal class SortedBytesMap(
private val longIdentifiers: Boolean,
private val bytesPerValue: Int,
private val sortedEntries: ByteArray
) {
复制代码
所谓hppc是High Performance Primitive Collection[7]的缩写,shark使用kotlin将其重写了。hppc只支持基本类型,所以没有了装、拆箱的性能损耗,相关集合操作也做了大量优化,其benchmark可以参考[8]。
再来看一下一个普通的对象在虚拟机中的内存开销有多大(ps:这还只是截图了一部分,一个int4个字节,1个long8个字节):

图15
前文提到,基于shark在解析大hprof时,性能依然不够理想,需要做进一步的优化。 先来分析一下shark的使用场景和我们解析需求的差异:
LeakCanary中shark只用于解析单一泄漏对象的引用链,而我们要分析大量对象的引用链。Shark对于结果的要求非常精准,而我们是线上大数据分析,允许丢弃个别对象的引用链。Shark对于镜像中的对象所有字段都进行解析,用于查询字段的值,而我们并不关心基础类型的值。
经过一番探索与实践,中途还去研究了MAT的源码,我们对其主要做了以下几点优化:
- GC root剪枝,由于我们搜索Path to GC Root时,是从GC Root自顶向下BFS,如
JavaFrame、MonitorUsed等此类GC Root可以直接剪枝。 - 基本类型、基本类型数组不搜索、不解析。
- 同类对象超过阈值时不再搜索。
- 增加预处理,缓存每个类的所有递归super class,减少重复计算。
- 将object ID的类型从
long修改为int,Android虚拟机的object ID大小只有32位,目前shark里使用的都是long来存储的,OOM时百万级对象的情况下,可以节省10M内存。
另外,还有几项实验中的调优项:
- 将
shark改用c++重写,从GC日志来看,大hprof解析时,GC还是十分频繁的,改用c++会降低这部分开销。 - 扩大okio segment池的大小,空间换时间,用更多的内存、来提升高频访问解析对象的性能。
经过以上优化,将解析时间在shark的基础上优化了2倍以上,内存峰值控制在100M以内。 用一张图总结解析的流程:
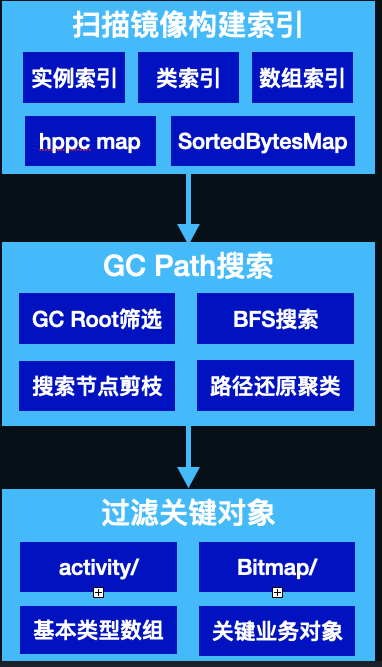
图16
分发与跟进
解析结果上传到server以后,还要做反混淆,聚类等工作。通过关键对象以及引用链,将问题聚合后自动分发给研发同学,分发的原则是引用链中最近提交代码的owner。图17&18摘录了跟进系统的关键信息:

图17
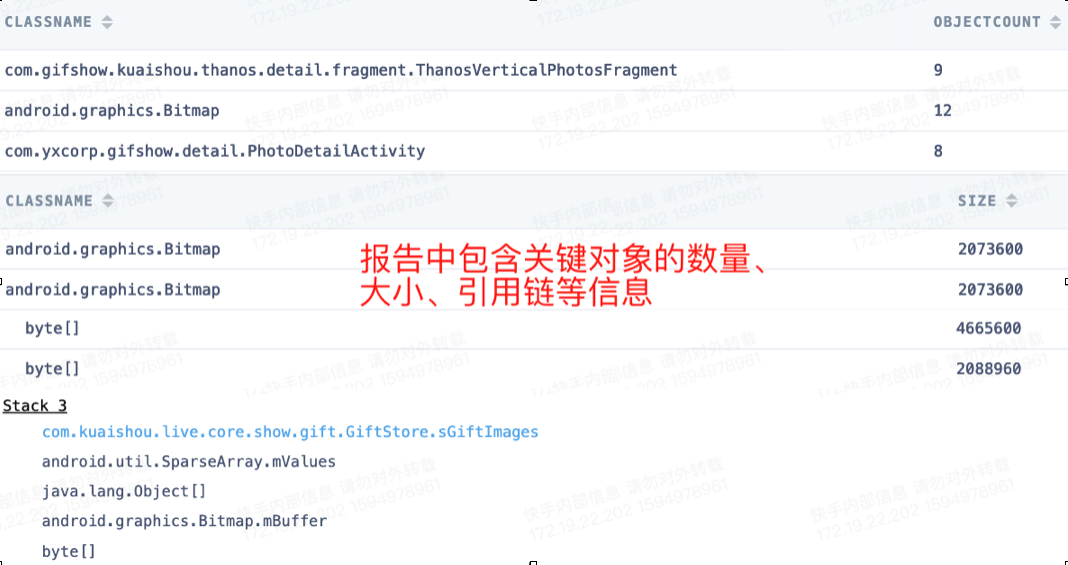
图18
参考
https://github.com/KwaiAppTeam/KOOM
//Matrix ResourceCanary没有解决dump hprof慢的问题,无法在线上使用
https://github.com/Tencent/matrix/wiki/Matrix-Android-ResourceCanary